1 ceph基本概念
1.1 为什么要使用ceph
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。 Ceph设计思想:集群可靠性、集群可扩展性、数据安全性、接口统一性、充分发挥存储设备自身的计算能力、去除中心化
1.2 Ceph架构介绍
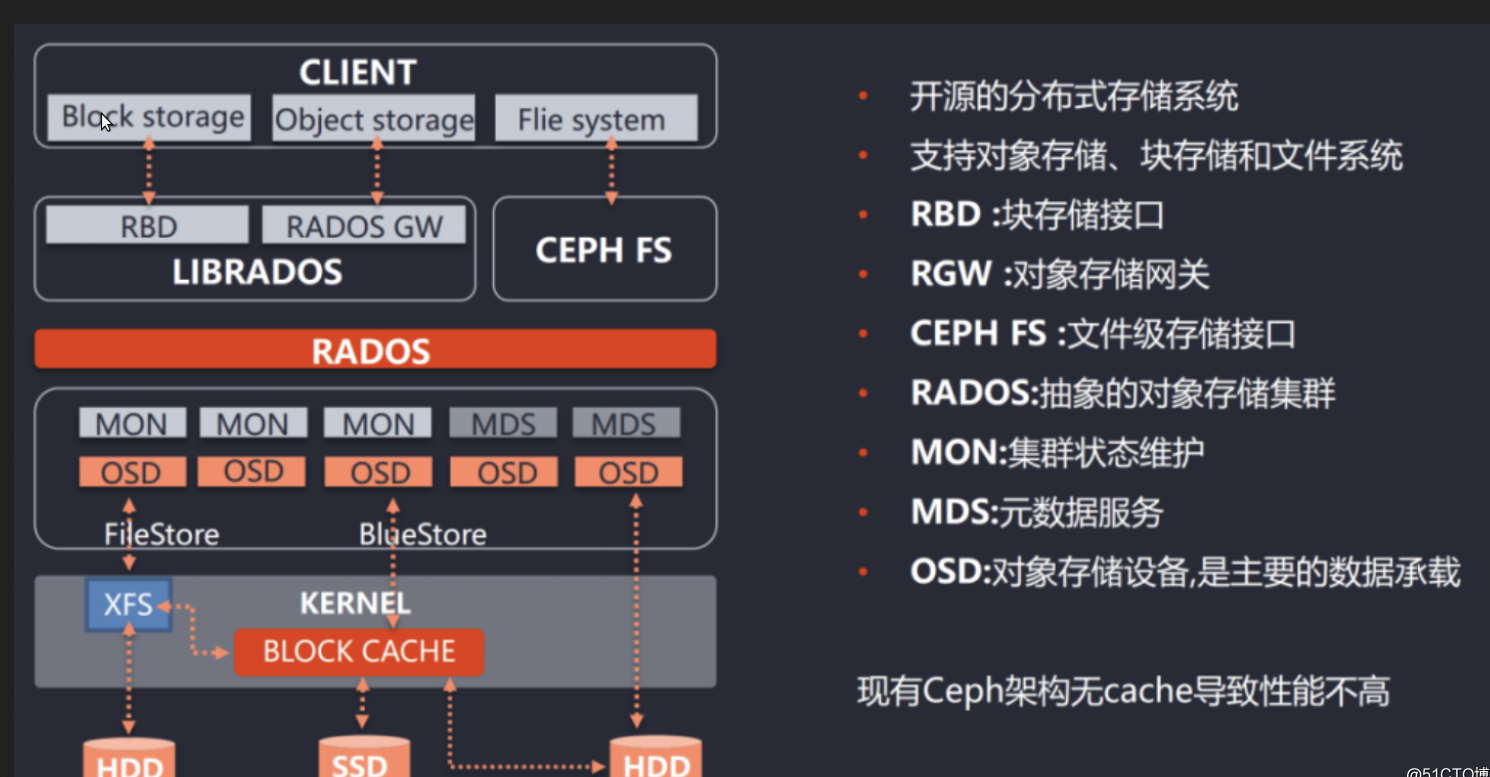
Ceph使用RADOS提供对象存储,通过librados封装库提供多种存储方式的文件和对象转换。外层通过RGW(Object,有原生的API,而且也兼容Swift和S3的API,适合单客户端使用)、RBD(Block,支持精简配置、快照、克隆,适合多客户端有目录结构)、CephFS(File,Posix接口,支持快照,社会和更新变动少的数据,没有目录结构不能直接打开)将数据写入存储
1.3 ceph特点
高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据
高可扩展性
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动
1.4 Ceph核心概念
RADOS
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
Librados
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
Crush
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code);
PG
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据;
Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
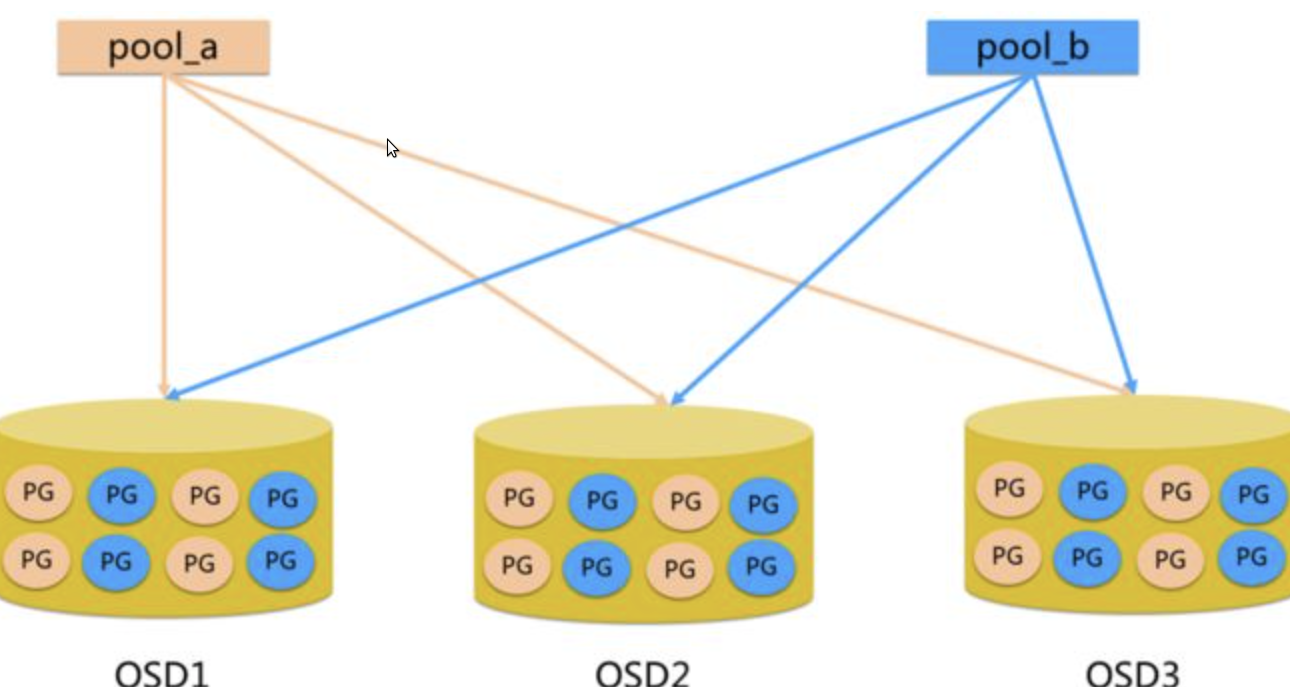
Pool、PG和OSD的关系:
一个Pool里有很多PG;
一个PG里包含一堆对象,一个对象只能属于一个PG;
PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
1.5 Ceph核心组件
OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;
Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权;
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务;
Mgr
ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、promethus
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
Admin
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
1.6 ceph三种存储类型
a.块存储(RBD)
优点:
通过Raid与LVM等手段,对数据提供了保护;
多块廉价的硬盘组合起来,提高容量;
多块磁盘组合出来的逻辑盘,提升读写效率;
缺点:
采用SAN架构组网时,光纤交换机,造价成本高;
主机之间无法共享数据;
使用场景
docker容器、虚拟机磁盘存储分配;
日志存储;
文件存储;
b.文件存储(CephFS)
优点:
造价低,随便一台机器就可以了;
方便文件共享;
缺点:
读写速率低;
传输速率慢;
使用场景
日志存储;
FTP、NFS;
其它有目录结构的文件存储
c.对象存储(Object)(适合更新变动较少的数据)
优点:
具备块存储的读写高速;
具备文件存储的共享等特性;
使用场景
图片存储;
视频存储;
2 nautilus版本Ceph安装
Luminous新版本特性 Bluestore ceph-osd的新后端存储BlueStore已经稳定,是新创建的OSD的默认设置。 BlueStore通过直接管理物理HDD或SSD而不使用诸如XFS的中间文件系统,来管理每个OSD存储的数据,这提供了更大的性能和功能。 BlueStore支持Ceph存储的所有的完整的数据和元数据校验。 BlueStore内嵌支持使用zlib,snappy或LZ4进行压缩。(Ceph还支持zstd进行RGW压缩,但由于性能原因,不为BlueStore推荐使用zstd) 集群的总体可扩展性有所提高。我们已经成功测试了多达10,000个OSD的集群。 ceph-mgr ceph-mgr是一个新的后台进程,这是任何Ceph部署的必须部分。虽然当ceph-mgr停止时,IO可以继续,但是度量不会刷新,并且某些与度量相关的请求(例如,ceph df)可能会被阻止。我们建议您多部署ceph-mgr的几个实例来实现可靠性。 ceph-mgr守护进程daemon包括基于REST的API管理。注:API仍然是实验性质的,目前有一些限制,但未来会成为API管理的基础。 ceph-mgr还包括一个Prometheus插件。 ceph-mgr现在有一个Zabbix插件。使用zabbix_sender,它可以将集群故障事件发送到Zabbix Server主机。这样可以方便地监视Ceph群集的状态,并在发生故障时发送通知。
2.1 部署前的准备
| os | hostname | ip | role |
|---|---|---|---|
| centos 7.4 | cephnode01 | 192.168.10.81 | ceph-deploy、monitor、Managers、rgw、mds |
| centos 7.4 | cephnode02 | 192.168.10.82 | monitor、Managers、rgw、mds |
| centos 7.4 | cephnode03 | 192.168.10.83 | monitor、Managers、rgw、mds |
(1)关闭防火墙:
systemctl stop firewalld systemctl disable firewalld
(2)关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0
(3)关闭NetworkManager
systemctl disable NetworkManager && systemctl stop NetworkManager
(4)添加主机名与IP对应关系: vim /etc/hosts
192.168.10.81 cephnode01
192.168.10.82 cephnode02
192.168.10.83 cephnode03
(5)设置主机名:
hostnamectl set-hostname cephnode01
hostnamectl set-hostname cephnode02
hostnamectl set-hostname cephnode03
(6)同步网络时间和修改时区
systemctl restart chronyd.service && systemctl enable chronyd.service
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
(7)设置文件描述符
echo "ulimit -SHn 102400" >> /etc/rc.local
cat >> /etc/security/limits.conf << EOF
* soft nofile 65535
* hard nofile 65535
EOF
(8)内核参数优化
cat >> /etc/sysctl.conf << EOF
kernel.pid_max = 4194303
vm.swappiness = 0
EOF
sysctl -p
(9)在cephnode01上配置免密登录到cephnode02、cephnode03
ssh-copy-id root@cephnode02
ssh-copy-id root@cephnode03
(10)read_ahead,通过数据预读并且记载到随机访问内存方式提高磁盘读操作
echo "8192" > /sys/block/sda/queue/read_ahead_kb
(11) 安装epel-release
yum -y install epel-release
2.2 安装Ceph集群
1、编辑内网yum源,将yum源同步到其它节点并提前做好yum makecache
cat > /etc/yum.repos.d/ceph.repo << "EOF"
[ceph-norch]
name=ceph-norch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[ceph-x86_64]
name=ceph-x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
EOF
yum makecache fast
2、安装ceph-deploy,在node01执行(确认ceph-deploy版本是否为2.0.1,)
yum -y install python-setuptools ceph-deploy
[root@cephnode01 ~]# ceph-deploy --version
2.0.1
3、创建一个my-cluster目录,所有命令在此目录下进行,在node01执行(文件位置和名字可以随意)
mkdir /my-cluster
cd /my-cluster
4、创建一个Ceph集群,在node01执行
ceph-deploy new cephnode01 cephnode02 cephnode03
5、安装Ceph软件(每个节点执行)
yum -y install ceph
[root@cephnode01 my-cluster]# ceph -v
ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
6、生成monitor检测集群所使用的的秘钥
ceph-deploy mon create-initial
7、安装Ceph Cli,方便执行一些管理命令
ceph-deploy admin cephnode01 cephnode02 cephnode03
8、部署mgr,用于管理集群
ceph-deploy mgr create cephnode01 cephnode02 cephnode03
9、部署rgw
yum install -y ceph-radosgw
10、部署MDS(cephFS)
ceph-deploy mds create cephnode01 cephnode02 cephnode03
ceph -s #查看集群状态
11、 添加osd
[root@cephnode01 my-cluster]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 30G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 29G 0 part
├─centos-root 253:0 0 27G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sdd 8:48 0 20G 0 disk
sr0 11:0 1 792M 0 rom
添加盘到ceph osd
ceph-deploy osd create --data /dev/sdb cephnode01
ceph-deploy osd create --data /dev/sdb cephnode02
ceph-deploy osd create --data /dev/sdb cephnode03
上面的命令是帮我们执行了一系列的动作
/usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdb
/bin/ceph-authtool --gen-print-key
/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new f5d5d872-63dd-486e-b3ca-6a9df6d2271c
/usr/sbin/vgcreate --force --yes ceph-c6fd0105-7c93-4d1b-8da4-9412c8f0fa5d /dev/sdb
/usr/sbin/lvcreate --yes -l 5119 -n osd-block-f5d5d872-63dd-486e-b3ca-6a9df6d2271c ceph-c6fd0105-7c93-4d1b-8da4-9412c8f0fa5d
/bin/ceph-authtool --gen-print-key
/bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-2
/bin/chown -h ceph
/bin/chown -R ceph
/bin/ln -s /dev/ceph-c6fd0105-7c93-4d1b-8da4-9412c8f0fa5d/osd-block-f5d5d872-63dd-486e-b3ca-6a9df6d2271c /var/lib/ceph/osd/ceph-2/block
/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-2/activate.monmap
/bin/ceph-authtool /var/lib/ceph/osd/ceph-2/keyring --create-keyring --name osd.2 --add-key AQDyuLBhMDM8ORAACsgWymqJ6Z01wLZ4aHZUeg==
/bin/chown -R ceph
/bin/chown -R ceph
/bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 2 --monmap /var/lib/ceph/osd/ceph-2/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-2/
/bin/chown -R ceph
/bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-c6fd0105-7c93-4d1b-8da4-9412c8f0fa5d/osd-block-f5d5d872-63dd-486e-b3ca-6a9df6d2271c --path /var/li
/bin/ln -snf /dev/ceph-c6fd0105-7c93-4d1b-8da4-9412c8f0fa5d/osd-block-f5d5d872-63dd-486e-b3ca-6a9df6d2271c /var/lib/ceph/osd/ceph-2/block
/bin/chown -h ceph
/bin/chown -R ceph
/bin/chown -R ceph
/bin/systemctl enable ceph-volume@lvm-2-f5d5d872-63dd-486e-b3ca-6a9df6d2271c
/bin/systemctl enable --runtime ceph-osd@2
查看添加的盘符
ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05846 root default
-3 0.01949 host cephnode01
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host cephnode02
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.01949 host cephnode03
2 hdd 0.01949 osd.2 up 1.00000 1.00000
[root@cephnode01 my-cluster]#
2.3 ceph配置文件
1、该配置文件采用init文件语法,#和;为注释,ceph集群在启动的时候会按照顺序加载所有的conf配置文件。 配置文件分为以下几大块配置。
global:全局配置。
osd:osd专用配置,可以使用osd.N,来表示某一个OSD专用配置,N为osd的编号,如0、2、1等。
mon:mon专用配置,也可以使用mon.A来为某一个monitor节点做专用配置,其中A为该节点的名称,ceph-monitor-2、ceph-monitor-1等。使用命令 ceph mon dump可以获取节点的名称。
client:客户端专用配置。
2、配置文件可以从多个地方进行顺序加载,如果冲突将使用最新加载的配置,其加载顺序为。
CEPH_CONF环境变量
-c 指定的位置
/etc/ceph/ceph.conf
~/.ceph/ceph.conf
./ceph.conf
3、配置文件还可以使用一些元变量应用到配置文件,如:cluster:当前集群名。
type:当前服务类型。id:进程的标识符。
host:守护进程所在的主机名。name:值为type.id。
4、ceph.conf详细参数
[global]#全局设置
fsid = xxxxxxxxxxxxxxx #集群标识ID
mon host = 10.0.1.1,10.0.1.2,10.0.1.3 #monitor IP 地址
auth cluster required = cephx #集群认证
auth service required = cephx #服务认证
auth client required = cephx #客户端认证
osd pool default size = 3 #最小副本数 默认是3
osd pool default min size = 1 #PG 处于 degraded 状态不影响其 IO 能力,min_size是一个PG能接受IO的最小副本数
public network = 10.0.1.0/24 #公共网络(monitorIP段)
cluster network = 10.0.2.0/24 #集群网络
max open files = 131072 #默认0#如果设置了该选项,Ceph会设置系统的max open fds
mon initial members = node1, node2, node3 #初始monitor (由创建monitor命令而定)
##############################################################
[mon]
mon data = /var/lib/ceph/mon/ceph-id
mon clock drift allowed = 1 #默认值0.05#monitor间的clock drift
mon osd min down reporters = 13 #默认值1#向monitor报告down的最小OSD数
mon osd down out interval = 600 #默认值300 #标记一个OSD状态为down和out之前ceph等待的秒数
##############################################################
[osd]
osd data = /var/lib/ceph/osd/ceph-id
osd mkfs type = xfs #格式化系统类型
osd max write size = 512 #默认值90 #OSD一次可写入的最大值(MB)
osd client message size cap = 2147483648 #默认值100 #客户端允许在内存中的最大数据(bytes)
osd deep scrub stride = 131072 #默认值524288 #在Deep Scrub时候允许读取的字节数(bytes)
osd op threads = 16 #默认值2 #并发文件系统操作数
osd disk threads = 4 #默认值1 #OSD密集型操作例如恢复和Scrubbing时的线程
osd map cache size = 1024 #默认值500 #保留OSD Map的缓存(MB)
osd map cache bl size = 128 #默认值50 #OSD进程在内存中的OSD Map缓存(MB)
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier" #默认值rw,noatime,inode64 #Ceph OSD xfs Mount选项
osd recovery op priority = 2 #默认值10 #恢复操作优先级,取值1-63,值越高占用资源越高
osd recovery max active = 10 #默认值15 #同一时间内活跃的恢复请求数
osd max backfills = 4 #默认值10 #一个OSD允许的最大backfills数
osd min pg log entries = 30000 #默认值3000 #修建PGLog是保留的最大PGLog数
osd max pg log entries = 100000 #默认值10000 #修建PGLog是保留的最大PGLog数
osd mon heartbeat interval = 40 #默认值30 #OSD ping一个monitor的时间间隔(默认30s)
ms dispatch throttle bytes = 1048576000 #默认值 104857600 #等待派遣的最大消息数
objecter inflight ops = 819200 #默认值1024 #客户端流控,允许的最大未发送io请求数,超过阀值会堵塞应用io,为0表示不受限
osd op log threshold = 50 #默认值5 #一次显示多少操作的log
osd crush chooseleaf type = 0 #默认值为1 #CRUSH规则用到chooseleaf时的bucket的类型
##############################################################
[client]
rbd cache = true #默认值 true #RBD缓存
rbd cache size = 335544320 #默认值33554432 #RBD缓存大小(bytes)
rbd cache max dirty = 134217728 #默认值25165824 #缓存为write-back时允许的最大dirty字节数(bytes),如果为0,使用write-through
rbd cache max dirty age = 30 #默认值1 #在被刷新到存储盘前dirty数据存在缓存的时间(seconds)
rbd cache writethrough until flush = false #默认值true #该选项是为了兼容linux-2.6.32之前的virtio驱动,避免因为不发送flush请求,数据不回写
#设置该参数后,librbd会以writethrough的方式执行io,直到收到第一个flush请求,才切换为writeback方式。
rbd cache max dirty object = 2 #默认值0 #最大的Object对象数,默认为0,表示通过rbd cache size计算得到,librbd默认以4MB为单位对磁盘Image进行逻辑切分
#每个chunk对象抽象为一个Object;librbd中以Object为单位来管理缓存,增大该值可以提升性能
rbd cache target dirty = 235544320 #默认值16777216 #开始执行回写过程的脏数据大小,不能超过 rbd_cache_max_dirty
3 ceph之rbd
RBD介绍 RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。RBD块设备类似磁盘可以被挂载。 RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。 RBD 就是 Ceph 里的块设备,一个 4T 的块设备的功能和一个 4T 的 SATA 类似,挂载的 RBD 就可以当磁盘用; resizable:这个块可大可小; data striped:这个块在Ceph里面是被切割成若干小块来保存,不然 1PB 的块怎么存的下; thin-provisioned:精简置备,1PB 的集群是能创建无数 1TB 的块的。其实就是块的大小和在 Ceph中实际占用大小是没有关系的,刚创建出来的块是不占空间,今后用多大空间,才会在 Ceph 中占用多大空间。举例:你有一个 32G 的 U盘,存了一个2G的电影,那么 RBD 大小就类似于 32G,而 2G 就相当于在 Ceph 中占用的空间 ; 块存储本质就是将裸磁盘或类似裸磁盘(lvm)设备映射给主机使用,主机可以对其进行格式化并存储和读取数据,块设备读取速度快但是不支持共享。 ceph可以通过内核模块和librbd库提供块设备支持。客户端可以通过内核模块挂在rbd使用,客户端使用rbd块设备就像使用普通硬盘一样,可以对其就行格式化然后使用典型的是云平台的块存储服务。 使用场景: 云平台(OpenStack做为云的存储后端提供镜像存储) K8s容器 map成块设备直接使用 ISCIS,安装Ceph客户端
3.1 Ceph RBD IO流程

(1)客户端创建一个pool,需要为这个pool指定pg的数量;
(2)创建pool/image rbd设备进行挂载;
(3)用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号;
(4)将每个object通过pg进行副本位置的分配;
(5)pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上;
(6)osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统;
(7)object的存储就变成了存储一个文rbd0.object1.file;
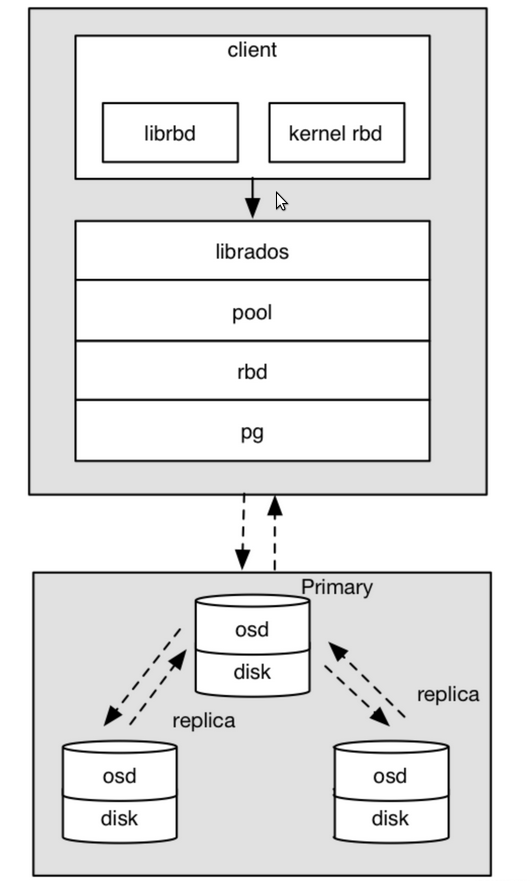
客户端写数据osd过程:
采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据;
在客户端本地同过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据保存在哪3个OSD上,这3个OSD分为主从的关系;
客户端与primay OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点;
3.2 RBD常用命令
| 命令 | 功能 |
|---|---|
| rbd create | 创建块设备映像 |
| rbd ls | 列出 rbd 存储池中的块设备 |
| rbd info | 查看块设备信息 |
| rbd diff | 可以统计 rbd 使用量 |
| rbd map | 映射块设备 |
| rbd showmapped | 查看已映射块设备 |
| rbd remove | 删除块设备 |
| rbd resize | 更改块设备的大小 |
3.3 RBD配置操作
3.3.1 RBD挂载到操作系统
1、创建rbd使用的pool
# ceph osd pool create rbd 32 32
# ceph osd pool application enable rbd rbd
2、创建一个块设备
# rbd create --size 10240 image01
3、查看块设备
# rbd ls
# rbd info image01
4、将块设备映射到系统内核
# rbd map image01
5、禁用当前系统内核不支持的feature
# rbd feature disable image01 exclusive-lock, object-map, fast-diff, deep-flatten
6、再次映射
# rbd map image01
7、格式化块设备镜像
# mkfs.xfs /dev/rbd0
8、mount到本地
# mount /dev/rbd0 /mnt
[root@cephnode03 ~]# df -h |grep rbd0
/dev/rbd0 10G 33M 10G 1% /mnt
9.查看object
rados -p rbd ls |grep rbd_data
10.查看文件最终落到那块osd上
3.3.2 取消挂载,释放rbd
1.umout
# umount /mnt
2.取消块设备和内核映射
# rbd unmap image01
3.删除RBD块设备
# rbd rm image01
# rbd ls
3.3.3 rbd快照配置
1、创建快照
rbd create --size 10240 image02
rbd snap create image02@image02_snap01
2、列出创建的快照
# rbd snap list image02
或
# rbd ls -l
3、查看快照详细信息
# rbd info image02@image02_snap01
4、克隆快照(快照必须处于被保护状态才能被克隆)
# rbd snap protect image02@image02_snap01
# rbd clone rbd/image02@image02_snap01 kube/image02_clone01
5、查看快照的children
# rbd children image02
6、去掉快照的parent
# rbd flatten kube/image02_clone01
7、恢复快照
# rbd snap rollback image02@image02_snap01
8、删除快照
# rbd snap unprotect image02@image02_snap01
# rbd snap remove image02@image02_snap01
3.3.4 导出导入RBD镜像
1、导出RBD镜像
# rbd export image02 /tmp/image02
2、导入RBD镜像
# rbd import /tmp/image02 rbd/image02 --image-format 2
3.3.5 rbd镜像扩容
rbd info image02
rbd image 'image02':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 39bf5f99a1c7
block_name_prefix: rbd_data.39bf5f99a1c7
format: 2
features: layering
op_features:
flags:
create_timestamp: Fri Dec 10 16:06:38 2021
access_timestamp: Fri Dec 10 16:06:38 2021
modify_timestamp: Fri Dec 10 16:06:38 2021
[root@cephnode01 my-cluster]# rbd resize rbd/image02 --size 15G
Resizing image: 100% complete...done.
[root@cephnode01 my-cluster]# rbd info image02
rbd image 'image02':
size 15 GiB in 3840 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 39bf5f99a1c7
block_name_prefix: rbd_data.39bf5f99a1c7
format: 2
features: layering
op_features:
flags:
create_timestamp: Fri Dec 10 16:06:38 2021
access_timestamp: Fri Dec 10 16:06:38 2021
modify_timestamp: Fri Dec 10 16:06:38 2021
3.5 CephFs介绍及配置
3.5.1 CephFs介绍
Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问. Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本. CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。 对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。 CephFS 架构 底层是核心集群所依赖的, 包括: OSDs (ceph-osd): CephFS 的数据和元数据就存储在 OSDs 上 MDS (ceph-mds): Metadata Servers, 管理着 CephFS 的元数据 Mons (ceph-mon): Monitors 管理着集群 Map 的主副本 Ceph 存储集群的协议层是 Ceph 原生的 librados 库, 与核心集群交互. CephFS 库层包括 CephFS 库 libcephfs, 工作在 librados 的顶层, 代表着 Ceph 文件系统.最上层是能够访问 Ceph 文件系统的两类客户端.
3.5.2 配置CephFS MDS
要使用 CephFS, 至少就需要一个 metadata server 进程。可以手动创建一个 MDS, 也可以使用 ceph-deploy 或者 ceph-ansible 来部署 MDS。
登录到ceph-deploy工作目录执行
# ceph-deploy mds create $hostname
3.5.3 部署Ceph文件系统
部署一个 CephFS, 步骤如下:
- 在一个 Mon 节点上创建 Ceph 文件系统.
- 若使用 CephX 认证,需要创建一个访问 CephFS 的客户端
- 挂载 CephFS 到一个专用的节点.
- 以 kernel client 形式挂载 CephFS
- 以 FUSE client 形式挂载 CephFS
创建一个Ceph文件系统
1、CephFS 需要两个 Pools - cephfs-data 和 cephfs-metadata, 分别存储文件数据和文件元数据
[root@cephnode01 my-cluster]# ceph osd pool create cephfs-data 16 16
pool 'cephfs-data' created
[root@cephnode01 my-cluster]# ceph osd pool create cephfs-metadata 16 16
pool 'cephfs-metadata' created
注:一般 metadata pool 可以从相对较少的 PGs 启动, 之后可以根据需要增加 PGs. 因为 metadata pool 存储着 CephFS 文件的元数据, 为了保证安全, 最好有较多的副本数. 为了能有较低的延迟, 可以考虑将 metadata 存储在 SSDs 上.
2、创建一个 CephFS, 名字为 cephfs:
# ceph fs new cephfs cephfs-metadata cephfs-data
3、验证至少有一个 MDS 已经进入 Active 状态
ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 1536k | 17.9G |
| cephfs-data | data | 0 | 17.9G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode01 |
| cephnode03 |
+-------------+
MDS version: ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
4、在 Monitor 上, 创建一个用户,用于访问CephFs
[root@cephnode01 my-cluster]# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs-data, allow rw pool=cephfs-metadata'
[client.cephfs]
key = AQD+9rZh/JMZIxAAnclzUdlpaCEFEqD/y9EmjA==
5、验证key是否生效
[root@cephnode01 my-cluster]# ceph auth get client.cephfs
[client.cephfs]
key = AQD+9rZh/JMZIxAAnclzUdlpaCEFEqD/y9EmjA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
exported keyring for client.cephfs
6、检查CephFs和mds状态
[root@cephnode01 my-cluster]# ceph mds stat
cephfs:1 {0=cephnode02=up:active} 2 up:standby
[root@cephnode01 my-cluster]# ceph fs ls
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
ceph fs status
3.5.4 kernel client形式挂载CephFS
1、创建挂载目录 cephfs
# mkdir /cephfs
2、挂载目录
# mount -t ceph 192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789:/ /cephfs/ -o name=cephfs,secret=AQD+9rZh/JMZIxAAnclzUdlpaCEFEqD/y9EmjA==
[root@gitlab ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 899M 0 899M 0% /dev
tmpfs 910M 12K 910M 1% /dev/shm
tmpfs 910M 19M 892M 3% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 27G 16G 12G 58% /
/dev/sda1 1014M 182M 833M 18% /boot
192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789:/ 18G 0 18G 0% /cephfs
3、自动挂载
# echo "192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0" | sudo tee -a /etc/fstab
4、验证是否挂载成功
# stat -f /cephfs
3.5.5 以FUSE client形式挂载CephFS
1、安装ceph-common
yum install -y ceph-common
2、安装ceph-fuse
yum install -y ceph-fuse
3、将集群的ceph.conf拷贝到客户端 【ceph集群外节点需要这个操作,集群内不用】
scp root@192.168.10.81:/etc/ceph/ceph.conf /etc/ceph/
chmod 644 /etc/ceph/ceph.conf
[root@cephnode01 my-cluster]# ceph auth get client.cephfs
[client.cephfs]
key = AQD+9rZh/JMZIxAAnclzUdlpaCEFEqD/y9EmjA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
exported keyring for client.cephfs
[root@cephnode01 my-cluster]# cat ceph.client.admin.keyring
[client.admin]
key = AQBrtrBhbSiDARAAeFTtEvKqYj9H1vP73jsTeg==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
4、使用 ceph-fuse 挂载 CephFS
[root@gitlab ceph]# ceph-fuse --keyring /etc/ceph/ceph.client.admin.keyring --name client.cephfs -m 192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789 /cephfs/
ceph-fuse[103680]: starting ceph client
5、验证 CephFS 已经成功挂载
[root@gitlab ceph]# stat -f /cephfs
文件:"/cephfs"
ID:0 文件名长度:255 类型:fuseblk
块大小:4194304 基本块大小:4194304
块:总计:4604 空闲:4604 可用:4604
Inodes: 总计:1 空闲:0
6、自动挂载
echo "none /cephfs fuse.ceph ceph.id=cephfs[,ceph.conf=/etc/ceph/ceph.conf],_netdev,defaults 0 0"| sudo tee -a /etc/fstab
或
echo "id=cephfs,conf=/etc/ceph/ceph.conf /mnt/ceph2 fuse.ceph _netdev,defaults 0 0"| sudo tee -a /etc/fstab
7、卸载
fusermount -u /cephfs
3.5.6 MDS主备与主主切换
(1)配置主主模式
当cephfs的性能出现在MDS上时,就应该配置多个活动的MDS。通常是多个客户机应用程序并行的执行大量元数据操作,并且它们分别有自己单独的工作目录。这种情况下很适合使用多主MDS模式。
(2)配置MDS多主模式
每个cephfs文件系统都有一个max_mds设置,可以理解为它将控制创建多少个主MDS。注意只有当实际的MDS个数大于或等于max_mds设置的值时,mdx_mds设置才会生效。例如,如果只有一个MDS守护进程在运行,并且max_mds被设置为两个,则不会创建第二个主MDS。
[root@cephnode01 ~]# ceph fs set cephfs max_mds 3
查看
[root@cephnode01 ~]# ceph -s
mds: cephfs:3 {0=cephnode02=up:active,1=cephnode03=up:active,2=cephnode01=up:active}
(3)配置备用MDS
即使有多个活动的MDS,如果其中一个MDS出现故障,仍然需要备用守护进程来接管。因此,对于高可用性系统,实际配置max_mds时,最好比系统中MDS的总数少一个。
但如果你确信你的MDS不会出现故障,可以通过以下设置来通知ceph不需要备用MDS,否则会出现insufficient standby daemons available告警信息:
# ceph fs set <fs> standby_count_wanted 0
(4)还原单主MDS
设置max_mds
# ceph fs set cephfs max_mds 1
4 Ceph Dashboard
4.1 Ceph Dashboard介绍
Ceph 的监控可视化界面方案很多----grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能,通过Dashboard可以获取Ceph集群的各种基本状态信息。 mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard.
4.2 配置Ceph Dashboard
1、在每个mgr节点安装
# yum install ceph-mgr-dashboard
2、开启mgr功能
# ceph mgr module enable dashboard
3、生成并安装自签名的证书
# ceph dashboard create-self-signed-cert
4、创建一个dashboard登录用户名密码
# [root@cephnode01 my-cluster]# ceph dashboard ac-user-create admin -i pas administrator
{"username": "admin", "lastUpdate": 1639467555, "name": null, "roles": ["administrator"], "password": "2b12$8VL6GpA/mAdRDLeyYwEl1eCsVAk4mqMAkdIAWSUPFGDkXytiK6gmS", "email": null}
5、禁用SSL
# ceph config set mgr mgr/dashboard/ssl false
6、查看服务访问方式
# ceph mgr services
修改默认配置命令(存在问题,无法修改)
指定集群dashboard的访问端口
# ceph config set mgr mgr/dashboard/server_port 7000
指定集群 dashboard的访问IP
# ceph config set mgr mgr/dashboard/server_addr 192.168.56.14

5 开启Object Gateway管理功能
安装 Ceph 对象网关
在你的管理节点的工作目录下,给 Ceph 对象网关节点安装Ceph对象所需的软件包。例如:
ceph-deploy install --rgw cephnode01
ceph-deploy install --rgw cephnode02
ceph-deploy install --rgw cephnode03
如果装不了,手动安装
[root@cephnode02 yum.repos.d]# yum -y install ceph-radosgw
ceph-common 包是它的一个依赖性,所以 ceph-deploy 也将安装这个包。 ceph 的命令行工具就会为管理员准备好。为了让你的 Ceph 对象网关节点成为管理节点,可以在管理节点的工作目录下执行以下命令:
ceph-deploy admin cephnode01
1、创建rgw用户
# radosgw-admin user create --uid=user01 --display-name=user01 --system
radosgw-admin user info --uid=user01
{
"user_id": "user01",
"display_name": "user01",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "user01",
"access_key": "V539WYL11NX0EFJC1BW1",
"secret_key": "27BblovggsMJhslh1AQzDdrIXu8jFzvPzSeJQ2w5"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"system": "true",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
2、提供Dashboard证书
ceph dashboard set-rgw-api-access-key -i akey
ceph dashboard set-rgw-api-secret-key -i skey
3、配置rgw主机名和端口(新建网关实例)
新建网关实例
ceph-deploy rgw create cephnode01
ceph-deploy rgw create cephnode02
ceph-deploy rgw create cephnode03
4、刷新web页面
s3操作参考http://docs.ceph.org.cn/install/install-ceph-gateway/
6 K8s对接Ceph存储
6.1 POD使用RBD做为持久数据卷
RBD支持ReadWriteOnce,ReadOnlyMany两种模式.不支持跨node和pod之间挂载的共享存储,支持滚动更新.
6.1.1 配置rbd-provider【k8s集群上操作】
在k8s集群安装ceph-common
tee /etc/yum.repos.d/ceph.repo << EOF
[ceph-norch]
name=ceph-norch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[ceph-x86_64]
name=ceph-x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
EOF yum -y install ceph-common
配置rbd-provisioner
cat > external-storage-rbd-provisioner.yaml <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: rbd-provisioner
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-provisioner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: [""]
resources: ["services"]
resourceNames: ["kube-dns","coredns"]
verbs: ["list", "get"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-provisioner
subjects:
- kind: ServiceAccount
name: rbd-provisioner
namespace: kube-system
roleRef:
kind: ClusterRole
name: rbd-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: rbd-provisioner
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: rbd-provisioner
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: rbd-provisioner
subjects:
- kind: ServiceAccount
name: rbd-provisioner
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: rbd-provisioner
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: rbd-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: rbd-provisioner
spec:
containers:
- name: rbd-provisioner
image: "quay.io/external_storage/rbd-provisioner:latest"
env:
- name: PROVISIONER_NAME
value: ceph.com/rbd
serviceAccount: rbd-provisioner
EOF
kubectl apply -f external-storage-rbd-provisioner.yaml
6.1.2 配置storageclass 【在cephnode01操作】
创建pod时,kubelet需要使用rbd命令去检测和挂载pv对应的ceph image,所以要在所有的worker节点安装ceph客户端ceph-common。将ceph的ceph.client.admin.keyring和ceph.conf文件拷贝到master的/etc/ceph目录下
scp /etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.conf root@192.168.10.71:/etc/ceph/
6.1.3 创建osd pool 在ceph的mon或者admin节点【在cephnode01操作】
[root@cephnode01 yum.repos.d]# ceph osd pool create kube 32 32
pool 'kube' created
rados lspools
ceph osd pool ls
6.1.4 创建k8s访问ceph的用户在ceph的mon或者admin节点 【在cephnode01操作】
ceph auth get-or-create client.kube mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=kube' -o ceph.client.kube.keyring
[client.kube]
key = AQA9jMBhoh/1CRAARxETYjZQmHug171jJc5XwA==
6.1.5 查看key在ceph的mon或者admin节点 【在cephnode01操作】
ceph auth get-key client.admin
ceph auth get-key client.kube
ceph auth get-key client.admin | base64 (这里获取的值要给k8s创建secret使用,也就是如下操作)
QVFCcnRyQmhiU2lEQVJBQWVGVHRFdktxWWo5SDF2UDczanNUZWc9PQ==
ceph auth get-key client.kube | base64 (这里获取的值要给k8s创建secret使用)
QVFBOWpNQmhvaC8xQ1JBQVJ4RVRZalpRbUh1ZzE3MWpKYzVYd0E9PQ==
6.1.6 创建admin secret 【k8s Master上操作】
cat secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret-admin
namespace: kube-system
type: "kubernetes.io/rbd"
data:
# ceph auth get-key client.admin | base64
key: QVFCcnRyQmhiU2lEQVJBQWVGVHRFdktxWWo5SDF2UDczanNUZWc9PQ==
---
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
namespace: kube-system
type: "kubernetes.io/rbd"
data:
# ceph auth add client.kube mon 'allow r' osd 'allow rwx pool=kube'
# ceph auth get-key client.kube | base64
key: QVFBOWpNQmhvaC8xQ1JBQVJ4RVRZalpRbUh1ZzE3MWpKYzVYd0E9PQ==
kubectl apply -f secret.yaml
6.1.7 配置StorageClass【k8s Master上操作】
tee storageclass-cephfs.yaml <<EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: dynamic-ceph-rdb
provisioner: ceph.com/rbd
parameters:
monitors: 192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789
pool: kube
adminId: admin
adminSecretNamespace: kube-system
adminSecretName: ceph-secret-admin
userId: kube
userSecretNamespace: kube-system
userSecretName: ceph-secret
fsType: ext4
imageFormat: "2"
imageFeatures: layering
EOF
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
dynamic-ceph-rdb ceph.com/rbd Delete Immediate false 66s
6.1.8 创建pvc
cat >ceph-rdb-pvc-test.yaml<<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: ceph-rdb-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: dynamic-ceph-rdb
resources:
requests:
storage: 2Gi
EOF
kubectl apply -f ceph-rdb-pvc-test.yaml
查看pvc
[root@k8s-master01 ceph-rdb]# kubectl get pvc |grep ceph-rdb-claim
ceph-rdb-claim Bound 2Gi RWO ceph-rbd 5m52s
6.1.9 挂载nginx测试
cat nginx-test-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod1
labels:
name: nginx-pod1
spec:
containers:
- name: nginx-pod1
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: ceph-rdb
mountPath: /usr/share/nginx/html
volumes:
- name: ceph-rdb
persistentVolumeClaim:
claimName: ceph-rdb-claim
kubectl apply -f nginx-test-pod.yaml
验证
[root@k8s-master01 ceph-rdb]# kubectl get pv |grep rbd
pvc-b800b3b3-3c1e-4468-8d72-d53996c39a02 2Gi RWO Delete Bound default/ceph-rdb-claim ceph-rbd 7m14s
[root@k8s-master01 ceph-rdb]# kubectl get pods |grep nginx-pod1
nginx-pod1 1/1 Running 1 5m18s
[root@cephnode01 ceph]# rbd ls --pool kube
kubernetes-dynamic-pvc-f0d64ccd-63f0-11ec-a894-d27f488b4766
6.1.10 pod使用rbd做持久化存在问题
rbd-provider不能自动在/etc/ceph/中挂载ceph的配置
6.2 POD使用CephFS做为持久数据卷
CephFS方式支持k8s的pv的3种访问模式ReadWriteOnce,ReadOnlyMany ,ReadWriteMany. linux内核需要4.10+,否则会出现无法正常使用的问题
6.2.1 CephFS创建两个Pool 【在cephnode01操作】
ceph osd pool create cephfs-date 16 16
ceph osd pool create cephfs-metadata 8 8
ceph osd lspools
6.2.2 创建一个CephFS 【在cephnode01操作】
ceph fs new cephfs cephfs-date cephfs-metadata
ceph fs ls
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
6.2.3 使用社区提供的cephfs-provisioner
cat >external-storage-cephfs-provisioner.yaml<<EOF
apiVersion: v1
kind: Namespace
metadata:
name: cephfs
labels:
name: cephfs
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cephfs-provisioner
namespace: cephfs
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: cephfs-provisioner
namespace: cephfs
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["create", "get", "delete"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-provisioner
namespace: cephfs
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: [""]
resources: ["services"]
resourceNames: ["kube-dns","coredns"]
verbs: ["list", "get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cephfs-provisioner
namespace: cephfs
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: cephfs-provisioner
subjects:
- kind: ServiceAccount
name: cephfs-provisioner
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-provisioner
subjects:
- kind: ServiceAccount
name: cephfs-provisioner
namespace: cephfs
roleRef:
kind: ClusterRole
name: cephfs-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cephfs-provisioner
namespace: cephfs
spec:
replicas: 1
selector:
matchLabels:
app: cephfs-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: cephfs-provisioner
spec:
containers:
- name: cephfs-provisioner
image: "quay.io/external_storage/cephfs-provisioner:latest"
env:
- name: PROVISIONER_NAME
value: ceph.com/cephfs
- name: PROVISIONER_SECRET_NAMESPACE
value: cephfs
command:
- "/usr/local/bin/cephfs-provisioner"
args:
- "-id=cephfs-provisioner-1"
serviceAccount: cephfs-provisioner
EOF
kubectl apply -f external-storage-cephfs-provisioner.yaml
[root@k8s-master01 cephfs]# kubectl get pod -n cephfs
NAME READY STATUS RESTARTS AGE
cephfs-provisioner-56f846d54b-h5zrw 1/1 Running 0 66s
6.2.4 获取ceph key【在cephnode01操作】
[root@cephnode01 my-cluster]# ceph auth get-key client.admin | base64
QVFCcnRyQmhiU2lEQVJBQWVGVHRFdktxWWo5SDF2UDczanNUZWc9PQ==
6.2.5 创建secret(一定要和storageclass在同一namespace)
cat > secret.yaml << EOF
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret-admin
namespace: cephfs
type: "kubernetes.io/rbd"
data:
# ceph auth get-key client.admin | base64
key: QVFCcnRyQmhiU2lEQVJBQWVGVHRFdktxWWo5SDF2UDczanNUZWc9PQ==
EOF
$ kubectl apply -f secret.yaml
6.2.6 配置 StorageClass
cat >storageclass-cephfs.yaml<<EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: dynamic-cephfs
provisioner: ceph.com/cephfs
parameters:
monitors: 192.168.10.81:6789,192.168.10.82:6789,192.168.10.83:6789
adminId: admin
adminSecretName: ceph-secret-admin
adminSecretNamespace: "cephfs"
claimRoot: /volumes/kubernetes
EOF
kubectl apply -f storageclass-cephfs.yaml
[root@k8s-master01 cephfs]# kubectl get sc |grep cephfs
dynamic-cephfs ceph.com/cephfs Delete Immediate false 15s
6.2.7 创建pvc测试
cat >cephfs-pvc-test.yaml<<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cephfs-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: dynamic-cephfs
resources:
requests:
storage: 2Gi
EOF
[root@k8s-master01 cephfs]# kubectl apply -f cephfs-pvc-test.yaml
cephFS支持·ReadWriteOnce、ReadOnlyMany和ReadWriteMany,可以允许多POD同时读写,适用于数据共享场景;
Ceph RBD 只支持ReadWriteOnce和ReadOnlyMany,允许多POD同时读,适用于状态应用资源隔离场景。
7 ceph日常运维管理
7.1 集群监控管理
集群整体运行状态
[root@cephnode01 my-cluster]# ceph -s
cluster:
id: 4f706b80-04bc-495d-9a34-f8dec17c96ae
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 34h)
mgr: cephnode01(active, since 3w), standbys: cephnode02, cephnode03
mds: cephfs:1 {0=cephnode03=up:active} 2 up:standby
osd: 3 osds: 3 up (since 8d), 3 in (since 8d)
rgw: 3 daemons active (cephnode01, cephnode02, cephnode03)
task status:
data:
pools: 8 pools, 224 pgs
objects: 333 objects, 73 MiB
usage: 3.2 GiB used, 57 GiB / 60 GiB avail
pgs: 224 active+clean
id:集群ID
health:集群运行状态,这里有一个警告,说明是有问题,意思是pg数大于pgp数,通常此数值相等。
mon:Monitors运行状态。
osd:OSDs运行状态。
mgr:Managers运行状态。
mds:Metadatas运行状态。
pools:存储池与PGs的数量。
objects:存储对象的数量。
usage:存储的理论用量。
pgs:PGs的运行状态
~]ceph -w
~] ceph health detail
PG状态
查看pg状态查看通常使用下面两个命令即可,dump可以查看更详细信息,如。
~]ceph pg dump
~] ceph pg stat
Pool状态
ceph osd pool stats
ceph osd pool stats
OSD状态
~]ceph osd stat
~] ceph osd dump
~]ceph osd tree
~] ceph osd df
Monitor状态和查看仲裁状态
ceph mon stat
ceph mon dump
ceph quorum_status
集群空间用量
~]ceph df
~] ceph df detail
7.2 集群配置管理(临时和全局,服务平滑重启)
有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用tell和daemon子命令来完成此需求。
1、查看运行配置
命令格式:
# ceph daemon {daemon-type}.{id} config show
命令举例:
# ceph daemon osd.0 config show
2、tell子命令格式
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。
命令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
命令举例:
# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
- daemon-type:为要操作的对象类型如osd、mon、mds等。
- daemon id:该对象的名称,osd通常为0、1等,mon为ceph -s显示的名称,这里可以输入*表示全部。
- injectargs:表示参数注入,后面必须跟一个参数,也可以跟多个
3、daemon子命令
使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
命令格式:
# ceph daemon {daemon-type}.{id} config set {name}={value}
命令举例:
# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false
7.3 集群操作
1、启动所有守护进程
# systemctl start ceph.target
2、按类型启动守护进程
# systemctl start ceph-mgr.target
# systemctl start ceph-osd@id
# systemctl start ceph-mon.target
# systemctl start ceph-mds.target
# systemctl start ceph-radosgw.target
7.4 添加和删除OSD
7.4.1 添加OSD
1、格式化磁盘
ceph-volume lvm zap /dev/sd<id>
2、进入到ceph-deploy执行目录/my-cluster,添加OSD
# ceph-deploy osd create --data /dev/sd<id> $hostname
7.4.2 删除OSD
1、调整osd的crush weight为 0
ceph osd crush reweight osd.<ID> 0.0
2、将osd进程stop
systemctl stop ceph-osd@<ID>
3、将osd设置out
ceph osd out <ID>
4、立即执行删除OSD中数据
ceph osd purge osd.<ID> --yes-i-really-mean-it
5、卸载磁盘
umount /var/lib/ceph/osd/ceph-?
7.5 扩容PG
ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
注:
1、扩容大小取跟它接近的2的N次方
2、在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常rebalancing。
7.6 Pool操作
7.6.1 列出存储池
ceph osd lspools
7.6.2 创建存储池
命令格式:
# ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
命令举例:
# ceph osd pool create rbd 32 32
7.6.3 设置存储池配额
命令格式:
# ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
命令举例:
# ceph osd pool set-quota rbd max_objects 10000
7.6.4 删除存储池
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
7.6.5 重命名存储池
ceph osd pool rename {current-pool-name} {new-pool-name}
7.6.6 查看存储池统计信息
rados df
7.6.7 给存储池做快照
ceph osd pool mksnap {pool-name} {snap-name}
7.6.8 删除存储池的快照
ceph osd pool rmsnap {pool-name} {snap-name}
7.6.8 获取存储池选项值
ceph osd pool get {pool-name} {key}
7.6.9 调整存储池选项值
ceph osd pool set {pool-name} {key} {value}
size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。
min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。
pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。
pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。
hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。
target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。
target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。
scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_min_interval 。
scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_max_interval 。
deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配置文件里的 osd_deep_scrub_interval 。
7.6.10 获取对象副本数
ceph osd dump | grep 'replicated size'
7.7 用户管理
Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
7.7.1 查看用户信息
查看所有用户信息
# ceph auth list
获取所有用户的key与权限相关信息
# ceph auth get client.admin
如果只需要某个用户的key信息,可以使用pring-key子命令
# ceph auth print-key client.admin
7.7.2 添加用户
# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring
# ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
7.7.3 修改用户权限
# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'
# ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
# ceph auth caps client.ringo mon ' ' osd ' '
7.7.4 删除用户
# ceph auth del {TYPE}.{ID}
其中, {TYPE} 是 client,osd,mon 或 mds 的其中一种。{ID} 是用户的名字或守护进程的 ID 。
7.8 增加和删除Monitor
一个集群可以只有一个 monitor,推荐生产环境至少部署 3 个。 Ceph 使用 Paxos 算法的一个变种对各种 map 、以及其它对集群来说至关重要的信息达成共识。建议(但不是强制)部署奇数个 monitor 。Ceph 需要 mon 中的大多数在运行并能够互相通信,比如单个 mon,或 2 个中的 2 个,3 个中的 2 个,4 个中的 3 个等。初始部署时,建议部署 3 个 monitor。后续如果要增加,请一次增加 2 个。
7.8.1 新增一个monitor
# ceph-deploy mon create $hostname
注意:执行ceph-deploy之前要进入之前安装时候配置的目录。/my-cluster
7.8.2 删除Monitor
# ceph-deploy mon destroy $hostname
注意: 确保你删除某个 Mon 后,其余 Mon 仍能达成一致。如果不可能,删除它之前可能需要先增加一个。
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-