
1 Prometheus
1.1 prometheus的组成
- prometheus server: 收集指标和存储时间序列数据,并提供查询接口
- clientLibrary: 客户端库
- push gateway: 短期存储指标数据.主要用于临时性的任务.
- exporters: 采集已有的第三方服务监控指标并暴露metrics
- Alertmanager: 告警
- web ui: 简单的web控制台
1.2 prometheus监控k8s架构图

k8S监控指标
Kubernetes本身监控
Node资源利用率
Node数量
Pods数量(Node)
资源对象状态
Pod监控
Pod数量(项目)
容器资源利用率
应用程序
1.3 prometheus监控k8s组件
| 监控指标 | 具体实现 | 举例 |
|---|---|---|
| pod性能 | cAdvisor | 容器cpu,内存利用率 |
| node性能 | node-exporter | 节点cpu,内存利用率 |
| k8s资源对象 | kube-state-metrics | pod,deployment,service |
| 服务可用性探测 | Blackbox-exporter | 支持HTTP、HTTPS、TCP、ICMP等方式探测目标地址服务可用性 |
服务发现:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
1.4 交付Exporters
1.4.1 部署kube-state-metrics
kube-state-metrics采集了k8s中各种资源对象的状态信息,只需要在master节点部署就行
准备镜像
docker pull quay.io/coreos/kube-state-metrics:v1.5.0
docker image tag quay.io/coreos/kube-state-metrics:v1.5.0 192.168.10.20:8081/prometheus/kube-state-metrics:v1.5.0
docker push 192.168.10.20:8081/prometheus/kube-state-metrics:v1.5.0
准备rbac资源清单
[root@k8s-master01 prometheus-k8s]# cat kube-state-metrics-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources:
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
准备Dp资源清单
cat kube-state-metrics-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v1.5.0
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.5.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.5.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: 192.168.10.20:8081/prometheus/kube-state-metrics:v1.5.0
imagePullPolicy: IfNotPresent
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer
image: lizhenliang/addon-resizer:1.8.3
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
# Config map for resource configuration.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
准备svc资源清单
cat kube-state-metrics-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "kube-state-metrics"
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metrics
应用资源配置清单
kubectl apply -f kube-state-metrics-rbac.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics-resizer created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
kubectl apply -f kube-state-metrics-deployment.yaml
deployment.apps/kube-state-metrics created
configmap/kube-state-metrics-config created
kubectl apply -f kube-state-metrics-service.yaml
service/kube-state-metrics created
验证
[root@k8s-master01 prometheus-k8s]# kubectl get pod -n kube-system -o wide |grep "kube-state-metrics"
kube-state-metrics-7596f7cdc-kmcfl 2/2 Running 0 2m16s 10.244.2.196 k8s-node02 <none> <none>
[root@k8s-master01 prometheus-k8s]# curl http://10.244.2.196:8080/healthz # 就绪性探测地址,可以额外对该地址添加存活性探针
ok
返回OK表示已经成功运行。
[root@k8s-master01 prometheus-k8s]# curl 10.244.2.196:8080/metrics |head #Prometheus 取监控数据的接口
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP kube_configmap_info Information about configmap.
# TYPE kube_configmap_info gauge
kube_configmap_info{namespace="kube-system",configmap="kubeadm-config"} 1
kube_configmap_info{namespace="kube-system",configmap="prometheus-config"} 1
kube_configmap_info{namespace="kube-system",configmap="kubelet-config-1.18"} 1
kube_configmap_info{namespace="kube-system",configmap="extension-apiserver-authentication"} 1
kube_configmap_info{namespace="kube-system",configmap="kube-flannel-cfg"} 1
kube_configmap_info{namespace="kube-public",configmap="cluster-info"} 1
kube_configmap_info{namespace="ingress-nginx",configmap="nginx-configuration"} 1
kube_configmap_info{namespace="blog",configmap="nginx-wp-config"} 1
100 8041 0 8041 0 0 6769k 0 --:--:-- --:--:-- --:--:-- 7852k
curl: (23) Failed writing body (0 != 2048)
1.4.2 部署node-exporter
使用node_exporter收集器采集节点资源利用率
方法一:
[root@k8s-master prometheus-k8s]# cat node_exporter.sh
#!/bin/bash
wget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
tar zxf node_exporter-0.17.0.linux-amd64.tar.gz
mv node_exporter-0.17.0.linux-amd64 /usr/local/node_exporter
cat <<EOF >/usr/lib/systemd/system/node_exporter.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable node_exporter
systemctl restart node_exporter
[root@k8s-master prometheus-k8s]# ./node_exporter.sh
方法二:
准备镜像
docker pull prom/node-exporter:v0.15.0
docker tag prom/node-exporter:v0.15.0 192.168.10.20:8081/prometheus/node-exporter:v0.15.0
docker push 192.168.10.20:8081/prometheus/node-exporter:v0.15.0
准备资源配置清单
# node-exporter采用daemonset类型控制器,部署在所有Node节点,且共享了宿主机网络名称空间
# 主要用途就是将宿主机的/proc,sys目录挂载给容器,是容器能获取node节点宿主机信息
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: node-exporter
namespace: kube-system
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
selector:
matchLabels:
daemon: "node-exporter"
grafanak8sapp: "true"
template:
metadata:
name: node-exporter
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
volumes:
- name: proc
hostPath:
path: /proc
type: ""
- name: sys
hostPath:
path: /sys
type: ""
containers:
- name: node-exporter
image: 192.168.10.20:8081/prometheus/node-exporter:v0.15.0
imagePullPolicy: IfNotPresent
args:
- --path.procfs=/host_proc
- --path.sysfs=/host_sys
ports:
- name: node-exporter
hostPort: 9100
containerPort: 9100
protocol: TCP
volumeMounts:
- name: sys
readOnly: true
mountPath: /host_sys
- name: proc
readOnly: true
mountPath: /host_proc
hostNetwork: true
应用资源配置清单
[root@k8s-master01 prometheus-k8s]# kubectl apply -f node-exporter.yaml
daemonset.apps/node-exporter created
[root@k8s-master01 prometheus-k8s]# kubectl get pod -n kube-system -l daemon="node-exporter" -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-82pjd 1/1 Running 0 46s 192.168.10.73 k8s-node02 <none> <none>
node-exporter-wd9lg 1/1 Running 0 46s 192.168.10.72 k8s-node01 <none> <none>
[root@k8s-master01 prometheus-k8s]# curl -s 192.168.10.72:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 1.5821e-05
go_gc_duration_seconds{quantile="0.25"} 1.8593e-05
go_gc_duration_seconds{quantile="0.5"} 2.7795e-05
go_gc_duration_seconds{quantile="0.75"} 3.1235e-05
go_gc_duration_seconds{quantile="1"} 4.2539e-05
go_gc_duration_seconds_sum 0.000155322
go_gc_duration_seconds_count 6
# HELP go_goroutines Number of goroutines that currently exist.
1.4.3 部署cadvisor
该exporter是通过和kubelet交互,取到Pod运行时的资源消耗情况,并将接口暴露给 Prometheus。
准备镜像
docker pull google/cadvisor:v0.28.3
docker tag google/cadvisor:v0.28.3 192.168.10.20:8081/prometheus/cadvisor:v0.28.3
docker push 192.168.10.20:8081/prometheus/cadvisor:v0.28.3
应用清单前,先在每个node上做以下软连接,否则服务可能报错
mount -o remount,rw /sys/fs/cgroup/
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
准备资源配置清单
[root@k8s-master01 prometheus-k8s]# cat prometheus-cadvisor.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cadvisor
namespace: kube-system
labels:
app: cadvisor
spec:
selector:
matchLabels:
name: cadvisor
template:
metadata:
labels:
name: cadvisor
spec:
hostNetwork: true
#------pod的tolerations与node的Taints配合,做POD指定调度----
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
#-------------------------------------
containers:
- name: cadvisor
image: 192.168.10.20:8081/prometheus/cadvisor:v0.28.3
imagePullPolicy: IfNotPresent
volumeMounts:
- name: rootfs
mountPath: /rootfs
readOnly: true
- name: var-run
mountPath: /var/run
- name: sys
mountPath: /sys
readOnly: true
- name: docker
mountPath: /var/lib/docker
readOnly: true
ports:
- name: http
containerPort: 4194
protocol: TCP
readinessProbe:
tcpSocket:
port: 4194
initialDelaySeconds: 5
periodSeconds: 10
args:
- --housekeeping_interval=10s
- --port=4194
terminationGracePeriodSeconds: 30
volumes:
- name: rootfs
hostPath:
path: /
- name: var-run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /data/docker
应用资源配置清单
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-cadvisor.yaml
daemonset.apps/cadvisor created
kubectl get pod -n kube-system -l name=cadvisor -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cadvisor-7t6qr 1/1 Running 0 27s 192.168.10.73 k8s-node02 <none> <none>
cadvisor-ql9ks 1/1 Running 0 27s 192.168.10.72 k8s-node01 <none> <none>
[root@k8s-master01 prometheus-k8s]# curl -s 192.168.10.73:4194/metrics | head -n 3
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="1e567c2",cadvisorVersion="v0.28.3",dockerVersion="18.09.7",kernelVersion="3.10.0-1127.19.1.el7.x86_64",osVersion="Alpine Linux v3.4"} 1
1.4.4 部署blackbox-exporter
Blackbox-exporter: 服务可用性探测,支持HTTP、HTTPS、TCP、ICMP等方式探测目标地址服务可用性
准备镜像
docker pull prom/blackbox-exporter:v0.15.1
docker tag prom/blackbox-exporter:v0.15.1 192.168.10.20:8081/prometheus/blackbox-exporter:v0.15.1
docker push 192.168.10.20:8081/prometheus/blackbox-exporter:v0.15.1
准备资源配置清单
[root@k8s-master01 prometheus-k8s]# cat prometheus-configmap_blackbox-exporter.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: kube-system
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
timeout: 2s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200,301,302]
method: GET
preferred_ip_protocol: "ip4"
tcp_connect:
prober: tcp
timeout: 2s
[root@k8s-master01 prometheus-k8s]# cat prometheus-configmap_blackbox-exporter.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: kube-system
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
timeout: 2s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200,301,302]
method: GET
preferred_ip_protocol: "ip4"
tcp_connect:
prober: tcp
timeout: 2s
[root@k8s-master01 prometheus-k8s]# cat prometheus-blackbox-exporter-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: blackbox-exporter
namespace: kube-system
labels:
app: blackbox-exporter
annotations:
deployment.kubernetes.io/revision: 1
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
volumes:
- name: config
configMap:
name: blackbox-exporter
defaultMode: 420
containers:
- name: blackbox-exporter
image: 192.168.10.20:8081/prometheus/blackbox-exporter:v0.15.1
imagePullPolicy: IfNotPresent
args:
- --config.file=/etc/blackbox_exporter/blackbox.yml
- --log.level=info
- --web.listen-address=:9115
ports:
- name: blackbox-port
containerPort: 9115
protocol: TCP
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: 100m
memory: 50Mi
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
readinessProbe:
tcpSocket:
port: 9115
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
[root@k8s-master01 prometheus-k8s]# cat prometheus-blackbox-exporter-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
selector:
app: blackbox-exporter
type: NodePort
ports:
- name: blackbox-port
protocol: TCP
port: 9115
targetPort: 9115
cat prometheus-blackbox-exporter-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
rules:
- host: blackbox.devopstack.cn
http:
paths:
- pathType: Prefix
path: "/"
backend:
serviceName: blackbox-exporter
servicePort: blackbox-port
应用资源配置清单
kubectl apply -f prometheus-configmap_blackbox-exporter.yaml
kubectl apply -f prometheus-blackbox-exporter-dp.yaml
kubectl apply -f prometheus-blackbox-exporter-svc.yaml
kubectl apply -f prometheus-blackbox-exporter-ingress.yaml
验证
cat /etc/hosts
192.168.10.72 blackbox.devopstack.cn
浏览器访问

1.5 部署prometheus监控k8s集群
常用的exporter prometheus不同于zabbix,没有agent,使用的是针对不同服务的exporter 正常情况下,监控k8s集群及node,pod,常用的exporter有四个: 1.kube-state-metrics 收集k8s集群master&etcd等基本状态信息 2.node-exporter 收集k8s集群node信息 3.cadvisor 收集k8s集群docker容器内部使用资源信息 4.blackbox-exporte 收集k8s集群docker容器服务是否存活
1.5.1 创建ConfigMap
[root@k8s-master01 prometheus-k8s]# cat prometheus-configmap.yaml
# Prometheus configuration format https://prometheus.io/docs/prometheus/latest/configuration/configuration/
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- /etc/config/rules/*.rules
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: kubernetes-nodes
scrape_interval: 30s
static_configs:
- targets:
- 192.168.10.72:9100
- 192.168.10.73:9100
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: 1:2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: 1:2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:80"]
执行
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-configmap.yaml
configmap/prometheus-config created
查看执行结果
[root@k8s-master01 prometheus-k8s]# kubectl get configmaps prometheus-config -n kube-system
NAME DATA AGE
prometheus-config 1 88s
热重读配置文件
congfigmap有热重启功能,这样每次改完配置文件都不需要重启prometheus的pod来重读配置了
- "--web.enable-lifecycle"在prometheus.deploy.yml的配置文件里面加上这段话就可以了
[root@prometheus]# cat reload-prometheus.sh
#!/bin/bash
kubectl apply -f configmap.yaml
sleep 60
curl -XPOST http://localhost:9090/-/reload
可以写个脚本,每次修改完配置文件的配置之后,执行一下脚本就可以同步生效了!
1.5.2 rbac授权
查看 prometheus-rbac.yaml
[root@k8s-master01 prometheus-k8s]# cat prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system
创建rbAC授权
kubectl apply -f prometheus-rbac.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
1.5.3 创建prometheus的Pod资源
准备镜像
docker pull prom/prometheus:v2.14.0
docker tag prom/prometheus:v2.14.0 192.168.10.20:8081/prometheus/prometheus:v2.14.0
docker image push 192.168.10.20:8081/prometheus/prometheus:v2.14.0
docker pull jimmidyson/configmap-reload:v0.1
docker tag jimmidyson/configmap-reload:v0.1 192.168.10.20:8081/prometheus/configmap-reload:v0.1
docker push 192.168.10.20:8081/prometheus/configmap-reload:v0.1
执行deploy资源生成
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-statefulset.yaml
[root@k8s-master01 prometheus-k8s]# cat prometheus-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: kube-system
labels:
k8s-app: prometheus
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v2.14.0
spec:
serviceName: "prometheus"
replicas: 1
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
containers:
- name: prometheus-server-configmap-reload
image: "192.168.10.20:8081/prometheus/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "192.168.10.20:8081/prometheus/prometheus:v2.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
# based on 10 running nodes with 30 pods each
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
- name: prometheus-rules
mountPath: /etc/config/rules
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-data
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "10Gi"
执行
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-statefulset.yaml
statefulset.apps/prometheus created
查看结果
[root@k8s-master01 prometheus-k8s]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-7mhzg 1/1 Running 4 73d
coredns-7ff77c879f-pcvvz 1/1 Running 4 73d
etcd-k8s-master01 1/1 Running 8 206d
kube-apiserver-k8s-master01 1/1 Running 8 206d
kube-controller-manager-k8s-master01 1/1 Running 8 206d
kube-flannel-ds-amd64-c2r48 1/1 Running 4 73d
kube-flannel-ds-amd64-pplwg 1/1 Running 6 73d
kube-flannel-ds-amd64-vgtv2 1/1 Running 4 73d
kube-proxy-6p7zj 1/1 Running 11 206d
kube-proxy-cdnfl 1/1 Running 13 206d
kube-proxy-wfblp 1/1 Running 13 206d
kube-scheduler-k8s-master01 1/1 Running 8 206d
prometheus-0 2/2 Running 0 3m45s
1.5.4 准备svc资源清单
[root@k8s-master01 prometheus-k8s]# cat prometheus-service.yaml
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: kube-system
labels:
kubernetes.io/name: "Prometheus"
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
k8s-app: prometheus
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-service.yaml
service/prometheus created
查看访问信息
[root@k8s-master01 prometheus-k8s]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.98.217.54 <none> 9090:31729/TCP 35s
访问浏览器查看

1.5.5 准备ingress资源清单
2 Grafana
2.1 部署grafana
准备镜像
docker pull grafana/grafana:7.4.5
docker tag grafana/grafana:7.4.5 192.168.10.20:8081/prometheus/grafana:7.4.5
docker push 192.168.10.20:8081/prometheus/grafana:7.4.5
准备资源配置清单
[root@k8s-master01 grafana]# cat grafana_rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
rules:
- apiGroups:
- "*"
resources:
- namespaces
- deployments
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana
subjects:
- kind: User
name: k8s-node
[root@k8s-master01 grafana]# cat grafana_rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
rules:
- apiGroups:
- "*"
resources:
- namespaces
- deployments
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana
subjects:
- kind: User
name: k8s-node
[root@k8s-master01 grafana]# cat grafana_dp.yaml
[root@k8s-master01 grafana]# cat grafana_dp.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: grafana
name: grafana
namespace: kube-system
spec:
serviceName: grafana
replicas: 1
selector:
matchLabels:
name: grafana
template:
metadata:
labels:
app: grafana
name: grafana
spec:
containers:
- name: grafana
image: 192.168.10.20:8081/prometheus/grafana:7.4.5
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: grafana-data
mountPath: /var/lib/grafana
subPath: grafana
securityContext:
fsGroup: 472
runAsUser: 472
volumeClaimTemplates:
- metadata:
name: grafana-data
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "10Gi"
[root@k8s-master01 grafana]# cat grafana_services.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-system
spec:
type: NodePort
ports:
- port : 3000
targetPort: 3000
nodePort: 30091
selector:
app: grafana
[root@k8s-master01 grafana]# cat grafana_ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: kube-system
spec:
rules:
- host: grafana.devopstack.cn
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
应用资源配置清单
kubectl apply -f grafana_rbac.yaml
kubectl apply -f grafana_dp.yaml
kubectl apply -f grafana_services.yaml
kubectl apply -f grafana_ingress.yaml
访问web
cat /etc/hosts
192.168.10.73 grafana.devopstack.cn
2.2 配置prometheus接入grafana
2.2.1 安装插件
[root@k8s-master01 grafana]# kubectl get pod -n kube-system|grep grafana
grafana-0 1/1 Running 0 86m
[root@k8s-master01 grafana]# kubectl exec -it grafana-0 /bin/bash -n kube-system
bash-5.0# grafana-cli plugins install grafana-kubernetes-app
bash-5.0# grafana-cli plugins install grafana-clock-panel
bash-5.0# grafana-cli plugins install grafana-piechart-panel
bash-5.0# grafana-cli plugins install briangann-gauge-panel
bash-5.0# grafana-cli plugins install natel-discrete-panel
重启pod
[root@k8s-master01 grafana]# kubectl delete pods grafana-0 -n kube-system
pod "grafana-0" deleted
查看是否还在
bash-5.0$ ls /var/lib/grafana/plugins
briangann-gauge-panel grafana-clock-panel grafana-kubernetes-app grafana-piechart-panel natel-discrete-panel
2.2.2 prometheus接入grafana
第一步:添加prometheus数据源第二步:测试数据源是否配置正确

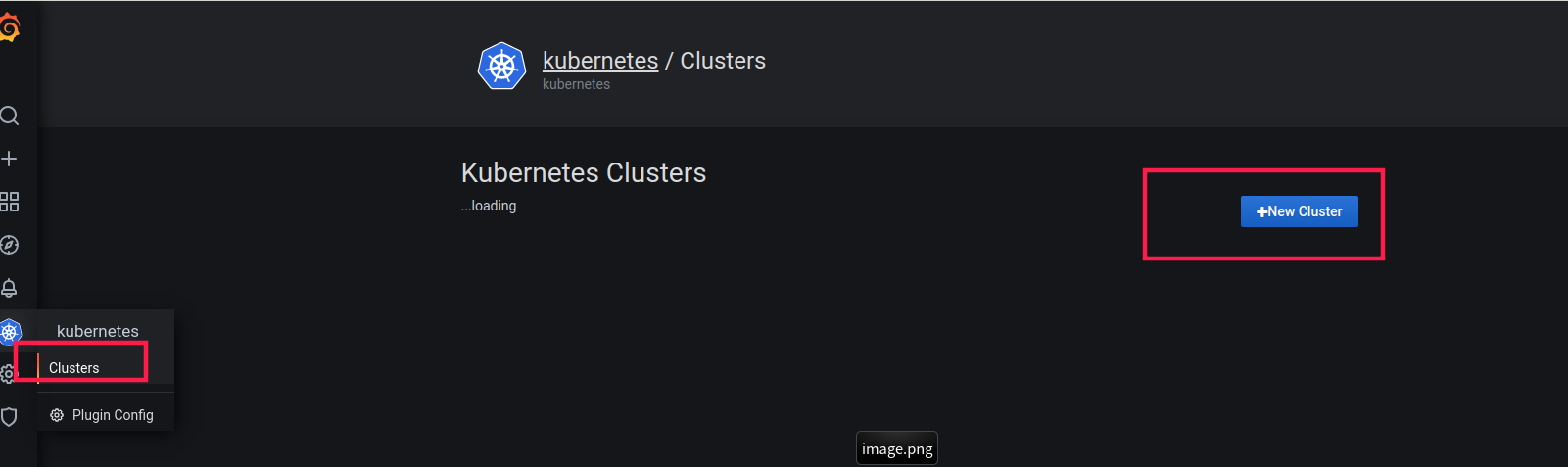
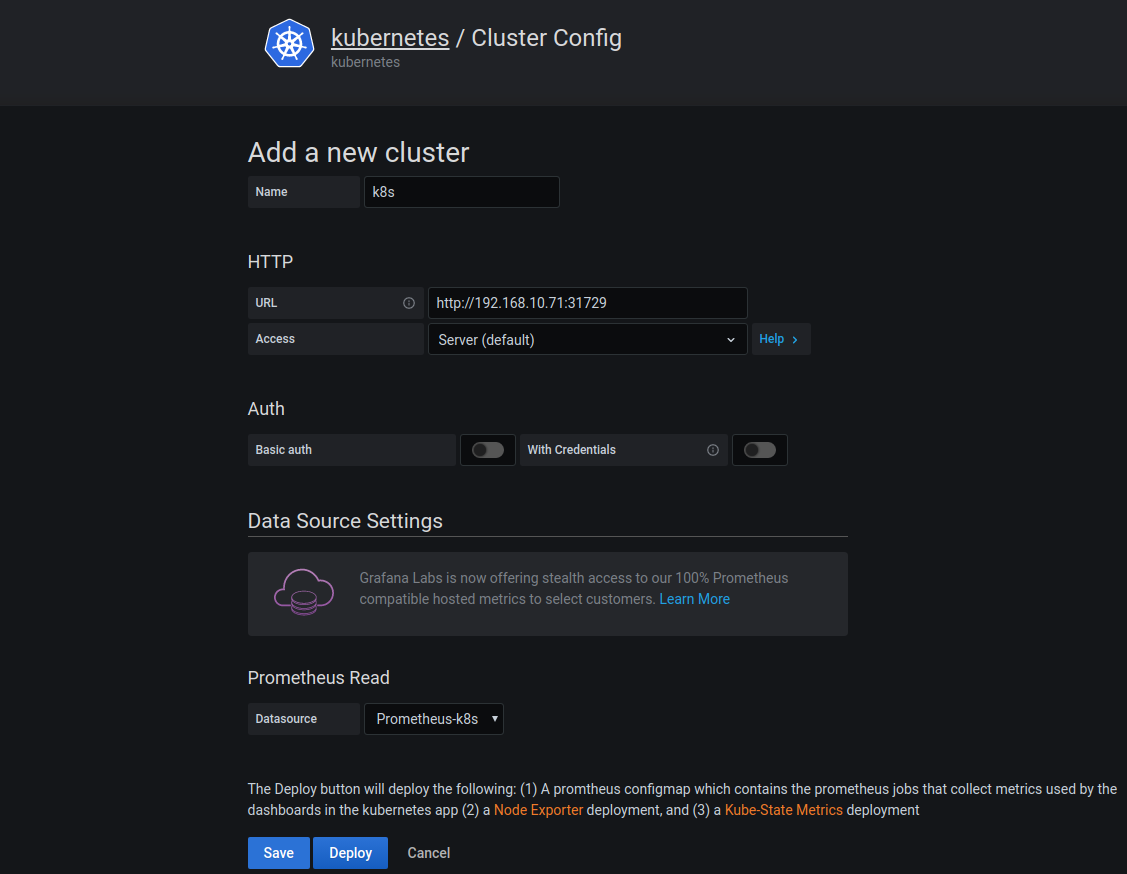
第三步:配置kubernetes app
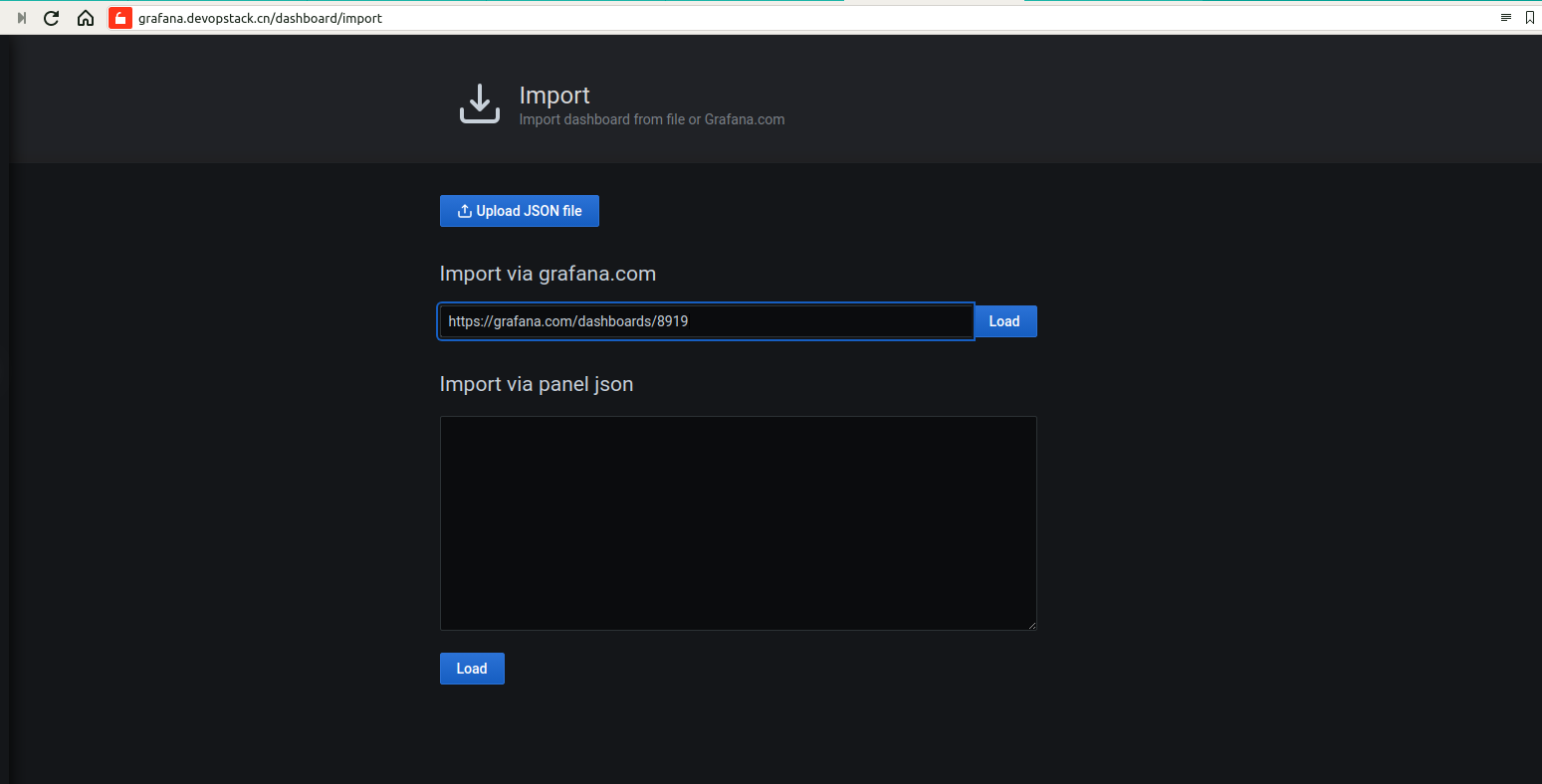
第四步:导入Kubernetes面板 Dashboard id:8919
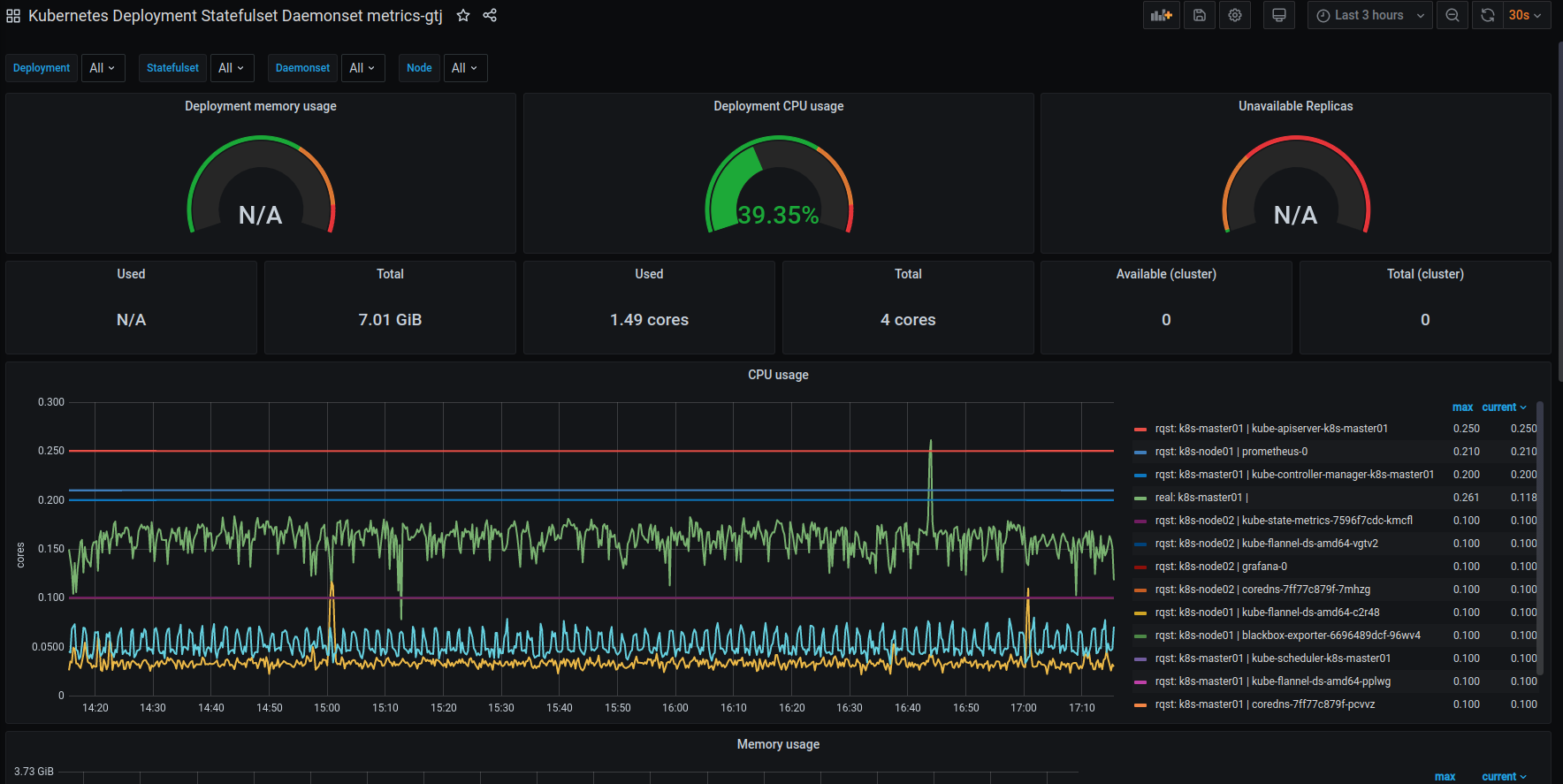
Kubernetes Deployment Statefulset Daemonset deployment
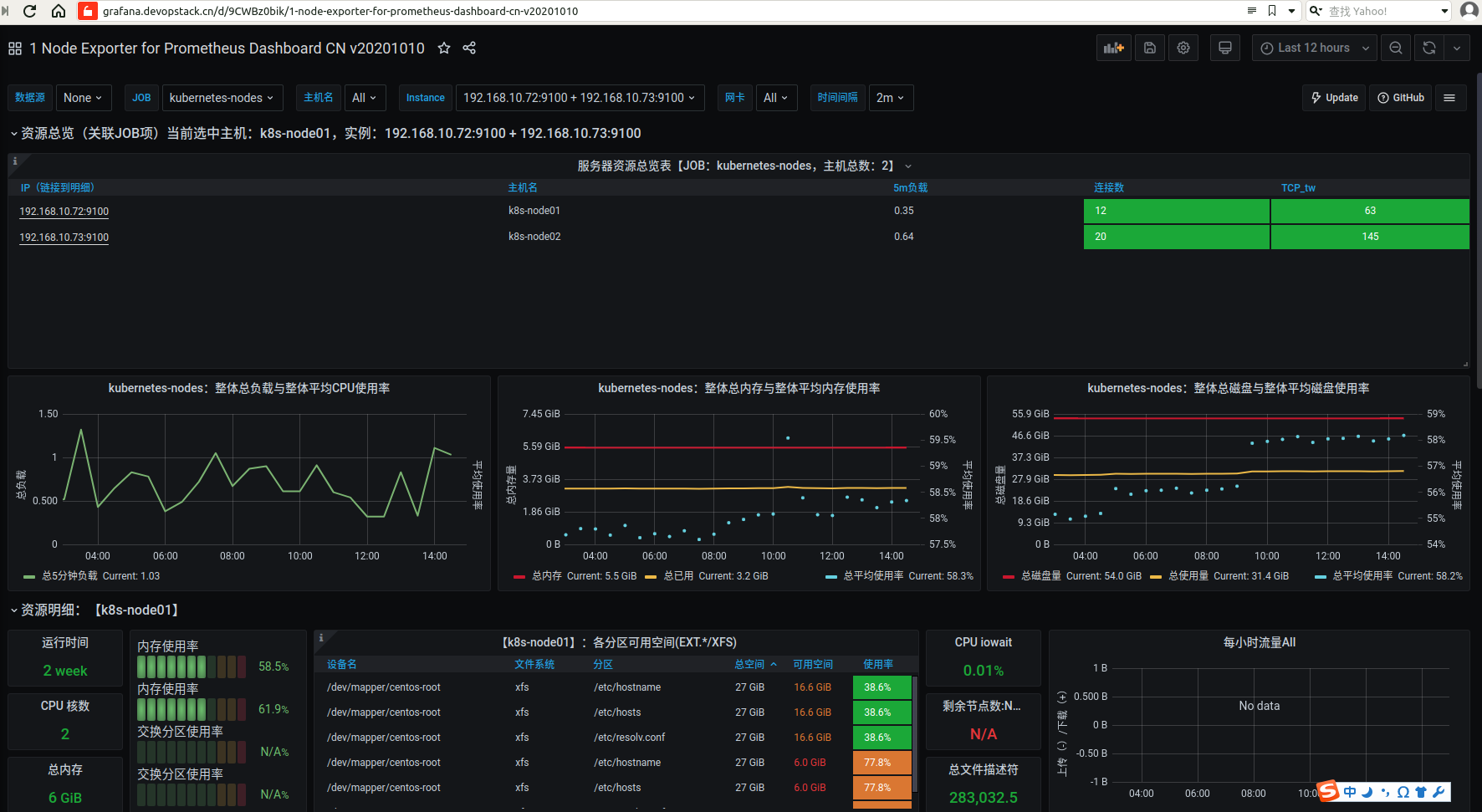
Node Exporter for Prometheus Dashboard
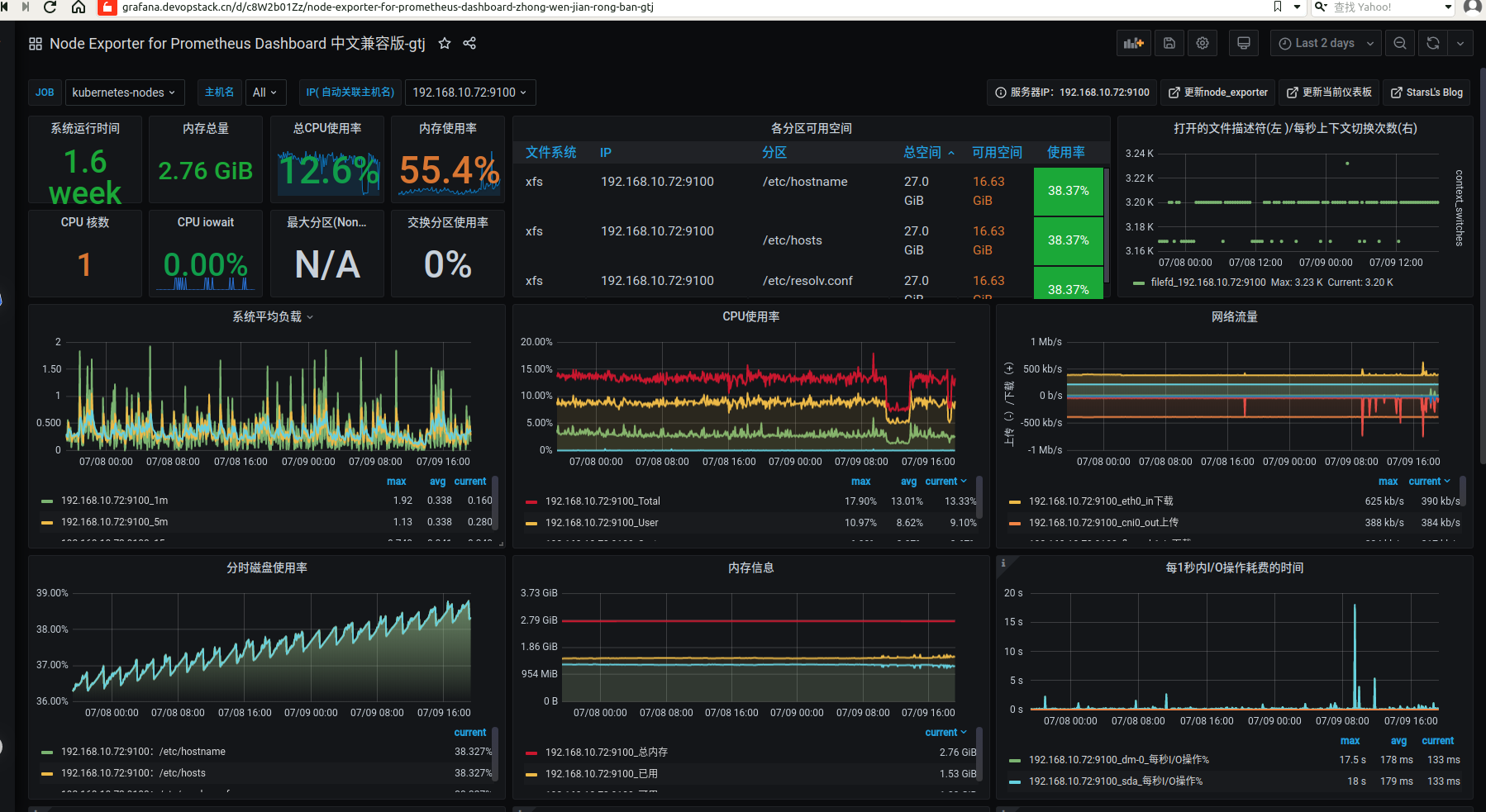
https://grafana.com/grafana/dashboards/11174
3 部署alertmanager
3.1 配置邮件告警
准备镜像
docker pull docker.io/prom/alertmanager:v0.14.0
docker tag docker.io/prom/alertmanager:v0.14.0 192.168.10.20:8081/prometheus/alertmanager:v0.14.0
docker push 192.168.10.20:8081/prometheus/alertmanager:v0.14.0
准备资源配置清单
# cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.devopstack.cn'
smtp_from: 'suixiaofeng@devopstack.cn'
smtp_auth_username: 'suixiaofeng@devopstack.cn'
smtp_auth_password: 'suixiaofeng@devopstack.cn'
receivers:
- name: default-receiver
email_configs:
- to: "suixiaofeng@devopstack.cn"
route:
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m
cat alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
cat alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
labels:
k8s-app: alertmanager
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v0.14.0
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
version: v0.14.0
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.14.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
containers:
- name: prometheus-alertmanager
image: "192.168.10.20:8081/prometheus/alertmanager:v0.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/alertmanager.yml
- --storage.path=/data
- --web.external-url=/
ports:
- containerPort: 9093
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: storage-volume
persistentVolumeClaim:
claimName: alertmanager
cat alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
selector:
k8s-app: alertmanager
type: "ClusterIP"
应用资源配置清单
kubectl apply -f alertmanager-configmap.yaml
kubectl apply -f alertmanager-pvc.yaml
kubectl apply -f alertmanager-deployment.yaml
kubectl apply -f alertmanager-service.yaml
查看pods
[root@k8s-master01 alertmanager]# kubectl get pods -n kube-system |grep aler
alertmanager-55dbb6c9f5-qlphl 2/2 Running 0 54m
修改某个告警参数触发告警
cat prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: kube-system
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "Instance {{ labels.instance }} 停止工作"
description: "{{labels.instance }} job {{ labels.job }} 已经停止5分钟以上."
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100)>5 for: 1m
labels:
severity: warning annotations:
summary: "Instance {{labels.instance }} : {{ labels.mountpoint }} 分区使用率过高"
description: "{{labels.instance }}: {{ labels.mountpoint }} 分区使用大于5% (当前值: {{value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree+node_memory_Cached+node_memory_Buffers) / node_memory_MemTotal * 100 < 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ labels.instance }} 内存使用率过高"
description: "{{labels.instance }}内存使用小于80% (当前值: {{ value }})"
- alert: NodeCPUUsage expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100)>60 for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{labels.instance }} CPU使用率过高"
description: "{{ labels.instance }}CPU使用大于60% (当前值: {{value }})"
这里我们故意把内存设置为小于80% 为了检查告警功能
[root@k8s-master01 prometheus-k8s]# kubectl apply -f prometheus-rules.yaml
热更新prometheus监控规则
[root@k8s-master01 alertmanager]# kubectl get services -n kube-system |grep prometheus
prometheus NodePort 10.98.217.54 <none> 9090:31729/TCP 8d
[root@k8s-master01 alertmanager]# curl -XPOST http://10.98.217.54:9090/-/reload
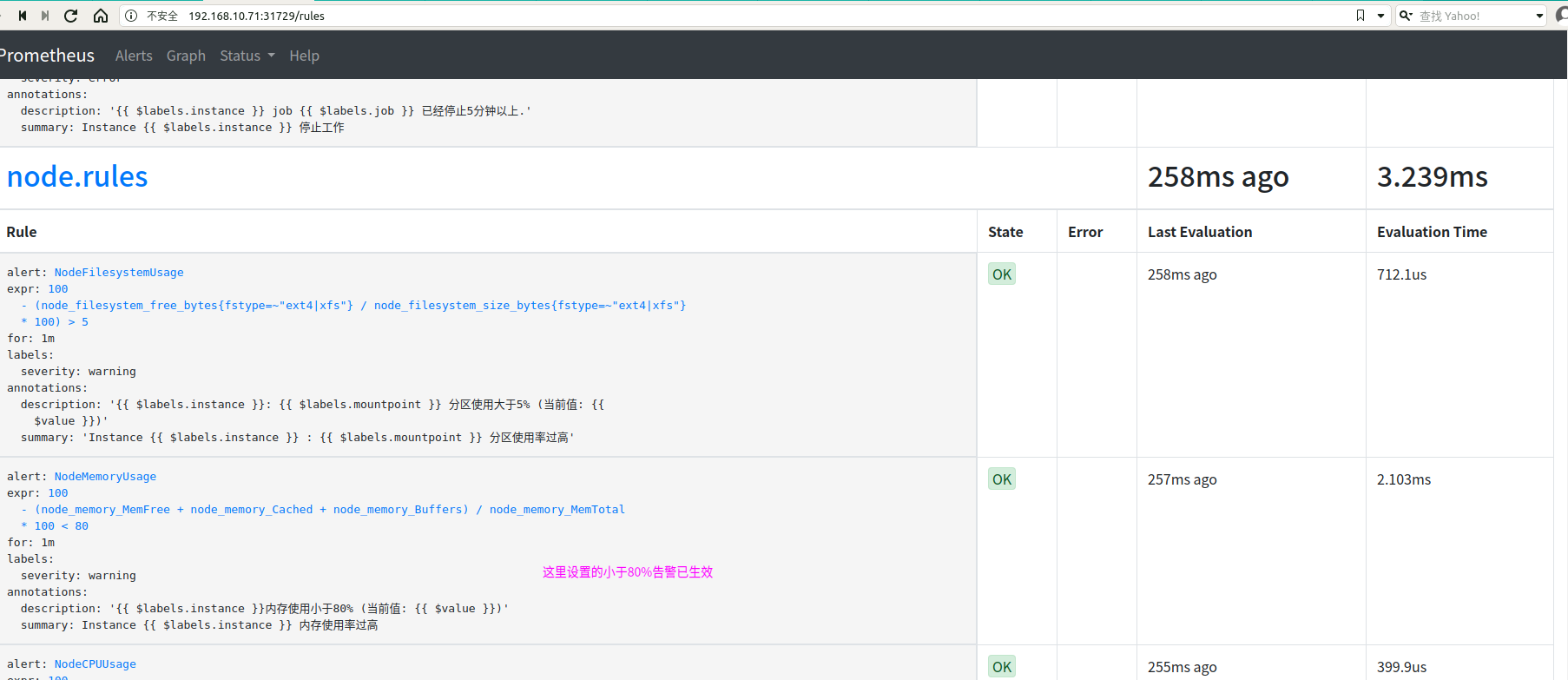
如下图可以看到告警已经触发
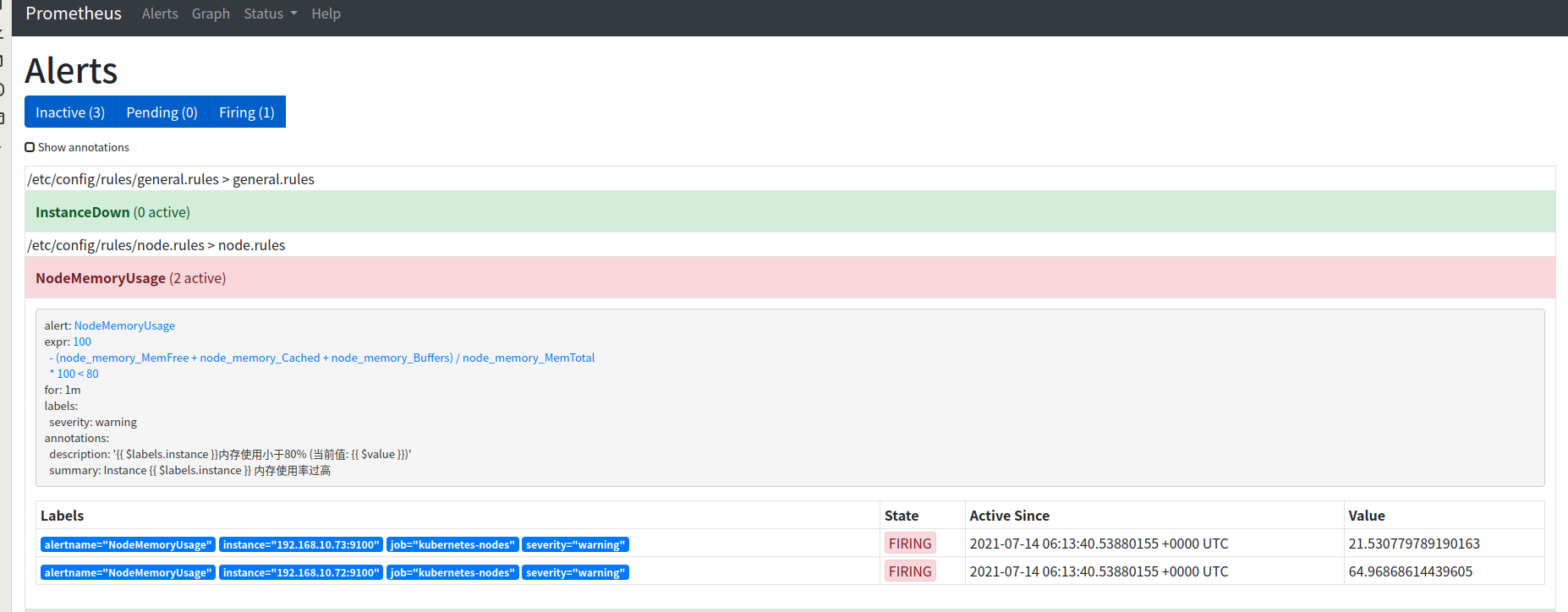
如下图 已经收到告警信息
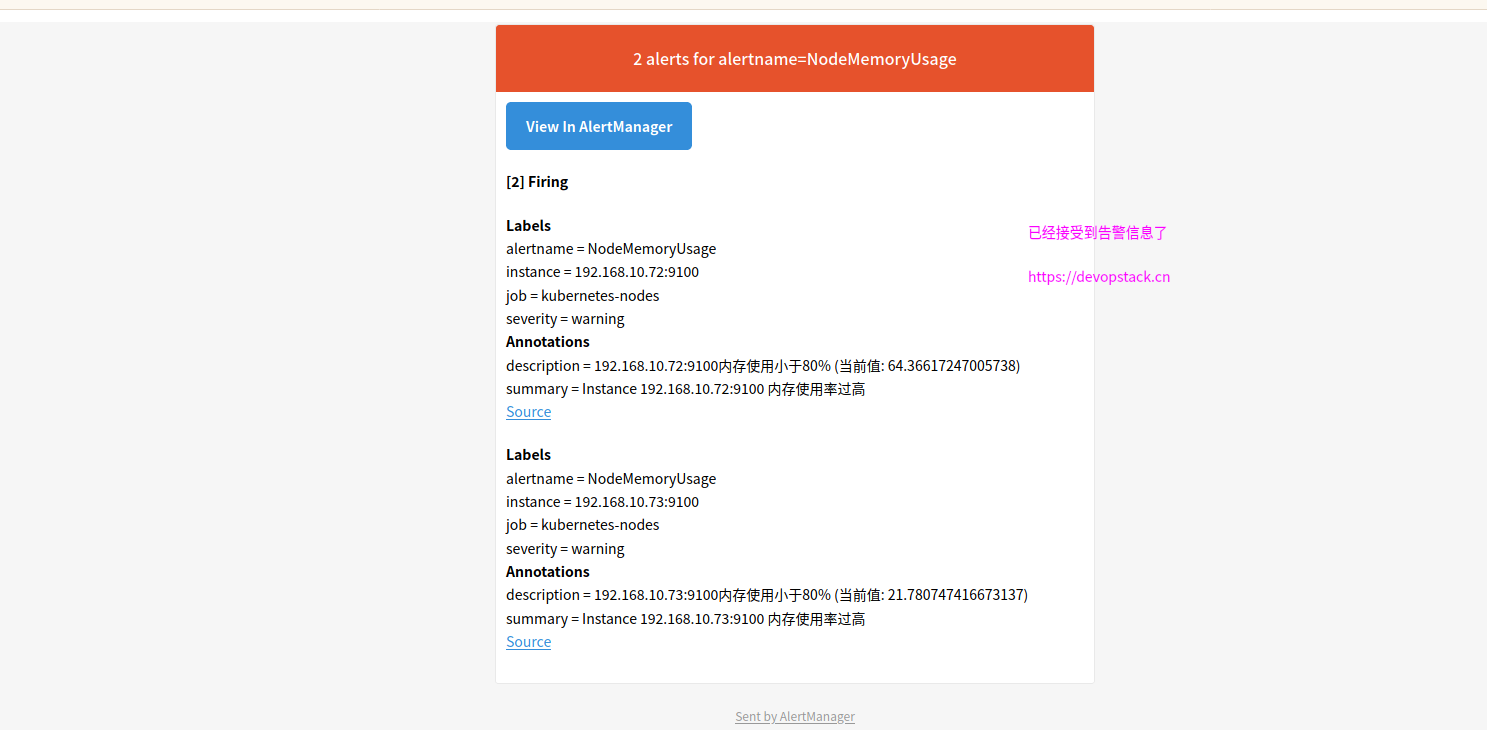
可以定制告警的内容模板,这快以后再研究.
3.2 配置钉钉告警
https://github.com/cnych/alertmanager-dingtalk-hook
3.3 配置微信告警
企业微信报警
注册企业微信,添加应用即可;
[root@node107 alert]# cat alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 6m
receiver: default
receivers:
- name: 'default'
email_configs:
- to: "xxx"
send_resolved: true
from: "xxx"
smarthost: "xxxx:25"
auth_username: "xxxxx"
auth_password: "xxxx"
wechat_configs:
- corp_id: 'xxxxx' ##企业id
to_party: '2' ## 看通讯录部门那编号是几
agent_id: '1000003'
api_secret: 'xxxxxxx'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-


