使用普罗米修斯进行警报分为两部分。 Prometheus服务器中的警报规则会向Alertmanager发送警报。 然后,Alertmanager管理这些警报,包括静音,禁止,聚合以及通过电子邮件,PagerDuty和HipChat等方法发送通知。
1 部署alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.22.2/alertmanager-0.22.2.linux-amd64.tar.gz
tar -xf alertmanager-0.22.2.linux-amd64.tar.gz -C /usr/local/
ln -s alertmanager-0.22.2.linux-amd64/ alertmanager
2 配置alertmanager
2.1 配置alertmanger通过企业微信告警
cat alertmanager.yml
global:
resolve_timeout: 5m
templates:
- '/usr/local/alertmanager/templates/*.tmpl'
route:
group_by: ['alertname','cluster','service']
group_wait: 5s
group_interval: 20s
repeat_interval: 3m
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '1'
agent_id: '1000002'
api_secret: 'xxxxxxx'
corp_id: 'xxxxxx'
参数说明:
corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看。
to_party: 需要发送的组。
agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
注意通过企业微信告警需要在应用里设置企业可信IP
告警消息通知模板
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range index,alert := .Alerts -}}
{{- if eq index 0 }}
========= 异常告警 =========
触发时间: {{ (alert.StartsAt.Add 28800e9).Format "2010-01-02 15:04:05" }}
告警类型: {{ alert.Labels.alertname }}
告警级别: {{alert.Labels.severity }}
告警详情: {{ alert.Annotations.description}} # 获取规则文件中的description
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- rangeindex, alert := .Alerts -}}
{{- if eqindex 0 }}
========= 告警恢复 =========
告警类型: {{ alert.Labels.alertname }} # 获取规则文件中的alert
告警级别: {{alert.Labels.severity }} # 获取规则文件中的severity
触发时间: {{ (alert.StartsAt.Add 28800e9).Format "2010-01-02 15:04:05" }} 恢复时间: {{ (alert.EndsAt.Add 28800e9).Format "2010-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
2.2 钉钉告警
docker安装钉钉报警插件(prometheus-webhook-dingtalk),启用一个名为:dingtalk的钉钉机器人。
docker run -d
--name dingtalk
--restart always
-p 8060:8060
timonwong/prometheus-webhook-dingtalk:master
--ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxxx(自己的钉钉机器人token)"
设置alertmanager.yml的route与receivers。
route属性用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: true
url: 'http://192.168.1.23:8060/dingtalk/webhook1/send'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
2.3 配置通过企业微信机器人告警
先安装docker
apt-get remove docker docker-engine docker.io containerd runc
apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# 清华源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \(lsb_release -cs) \
stable"
apt-get update
apt install docker-ce
systemctl start docker
systemctl enable docker
docker安装企业微信报警插件(webhook-adapter),启用一个名为:wechat的钉钉机器人。
docker run -d --name wechat --restart always -p 8080:80 guyongquan/webhook-adapter --adapter=/app/prometheusalert/wx.js=/wx=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=e8d95bb4-9b39-4611-b102-520922da5184
root@jelly02:/usr/local/alertmanager# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ca8e36698d0f guyongquan/webhook-adapter "node /app/index.js …" 17 minutes ago Up 17 minutes
配置
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: true
url: 'http://192.168.33.12:8080/adapter/wx'
2.4 配置alertmanger邮件告警
先获取邮箱的客户端授权密码
然后配置alertmanger
cat /usr/local/alertmanager/alertmanager.yml
smtp_smarthost: 'smtp.qiye.163.com:25'
smtp_from: 'suixiaofeng@devopstack.cn'
smtp_auth_username: 'suixiaofeng@devopstack.cn'
smtp_auth_password: 'Bnf3xxxxx'
smtp_require_tls: true
smtp_hello: '163.com'
route:
group_by: ['alertname','cluster','service']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'ops_mail'
receivers:
- name: 'ops_mail'
email_configs:
- send_resolved: true
to: getingjin@unionpaysmart.com,zhouhao@unionpaysmart.com
headers:{ Subject: "[{{ .Status | toUpper }}{{ if eq .Status \"firing\" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values }}" }
html: '{{ template "email.default.html" . }}'
然后重启alertmanger
3 配置prometheus
Prometheus的配置主要由prometheus.yml主文件和rule.yml告警规则文件组成.
修改prometheus的配置文件prometheus.yml
# Alertmanager configuration
# 改为alertmanager的地址
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
# 指定规则文件
rule_files:
- rules/*.yml
rule.yml
告警规则文件罗列了CPU,服务状态,内存,磁盘的告警规则
groups:
# 报警组组名称
- name: node_rule
#报警组规则
rules:
#告警名称,需唯一
- alert: Server Status
#promQL表达式
expr: up == 0
#满足此表达式持续时间超过for规定的时间才会触发此报警
for: 10s
labels:
#严重级别
severity: critical
annotations:
#发出的告警标题
summary: "实例 {{ labels.instance }} 关闭"
#发出的告警内容
description: "系统 {{labels.instance }}: 实例关闭"
ip: "{{ labels.ip }}"
- alert: Memory Usage
expr: 100 - round(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100)>80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{labels.instance }} 内存使用率过高"
description: "实例内存使用率超过 80% (当前值为: {{ value }}%)"
ip: "{{labels.ip }}"
- alert: CPU Usage
expr: 100 - round(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{ labels.instance }} CPU使用率过高"
description: "实例CPU使用率超过 80% (当前值为: {{value }}%)"
ip: "{{ labels.ip }}"
- alert: Disk Usage
expr: 100 - round(node_filesystem_free_bytes{fstype=~"ext3|ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}
*100)>80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{labels.instance }} 磁盘使用率过高"
description: "实例磁盘使用率超过 80% (当前值为: {{ value }}%)"
ip: "{{labels.ip }}"
然后重启prometheus服务。
4 启动alertmanager
cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager service
After=network.target prometheus.service
[Service]
User=monitor
Group=monitor
KillMode=control-group
Restart=on-failure
RestartSec=60
# 参数指定的 data 目录不能加双引号
ExecStart=/opt/apps/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmana
检查启动配置
root@jelly02:/usr/local/alertmanager# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 1 receivers
- 1 templates
SUCCESS
启动alertmanager
service alertmanager start
5 测试报警
5.1 通过微信机器人的测试告警
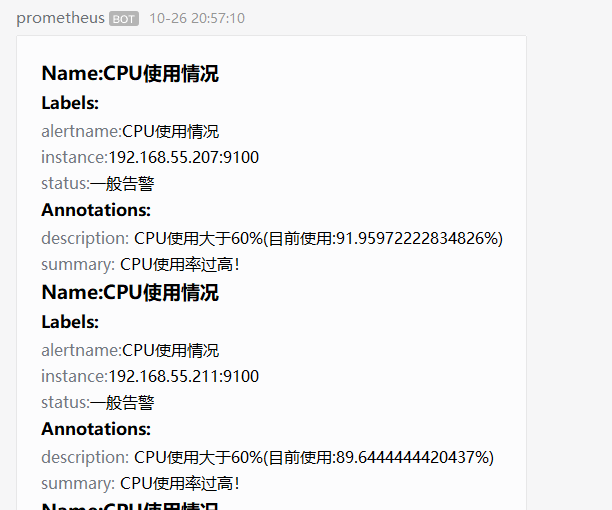
5.2 通过邮件告警结果







